看下 FUSE 的相关知识。
Filesystem In Userspace 也就是 fuse,是 linux 的一个内核模块。
Fuse 的优势在于:
- 允许非管理员权限去 mount 一个文件系统,例如 overlayfs
- 允许不通过内核实现一个文件系统
但是 Fuse 并不是在用户态访问文件系统,在调用文件系统时,依然需要陷入内核访问 VFS,并通过内核完成 IO。Fuse 在用户态做的是将内核传递的 fuse request 处理,并调用 VFS。
To FUSE or not to FUSE - Analysis and Performance Characterization of the FUSE User-Space File System Framework
2
fuse 的内核部分是 fuse.ko,会注册三个文件系统的类型:fuse、fuseblk、fusectl,它们在 /proc/filesystems 中都可见。fuse 类型的文件系统并不需要下层的块设备,而 fuseblk 类型的文件系统则需要。
fuseblk provides following features:
- Locking the block device on mount and unlocking on release;
- Sharing the file system for multiple mounts;
- Allowing swap files to bypass the file system in accessing the underlying device;
fuse 和 fuseblk 都是一些不同的 FUSE 文件系统的 proxy,所以后面统称为 FUSE。
几点说明:
- FUSE 文件系统的名字一般是
[fuse|fusectl].$NAME。 - /dev/fuse 是一个块设备,被用来支持用户态的 FUSE daemon 和内核之间的通信。简单来说,用户态的 daemon 会从 /dev/fuse 中读出请求,进行处理,然后再写回到 /dev/fuse 中。
这个经典的图,是 FUSE 的链路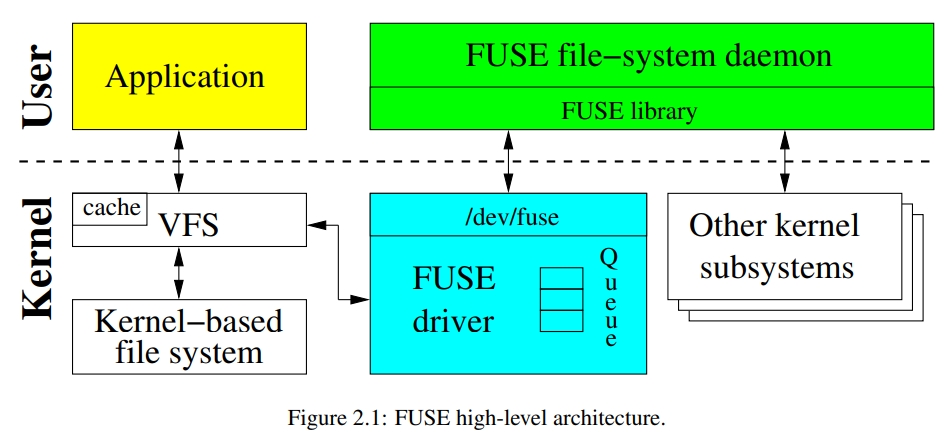
When a user application performs some operation on a mounted FUSE file system, the VFS routes the operation to FUSE’s kernel (file system) driver. The driver allocates a FUSE request structure and puts it in a FUSE queue. At this point, the
process that submitted the operation is usually put in a wait state.
FUSE’s user-level daemon then picks the request from the kernel queue by reading from/dev/fuseand processes the request. Processing the request might require re-entering the kernel again: for example, in case of a stackable FUSE file system, the daemon submits operations to the underlying file system (e.g., Ext4); or in case of a block-based FUSE file system, the daemon reads or writes from the block device; and in case of a network or in-memory file system, the FUSE daemon might still need to re-enter the kernel to obtain certain system services (e.g., create a socket or get the time of day).
When done with processing the request, the FUSE daemon writes the response back to/dev/fuse; FUSE’s kernel driver then marks the request as completed, and wakes up the original user process which submitted the request.
一些文件系统的操作并不需要和用户态的 FUSE daemon 交流,就可以完成。例如,读一个之前读过的文件,因为它的 page 已经被存在 page cache 里面了,所以就不需要再把请求 forward 给 FUSE driver 了。这里可能被 cache 的不仅包括 data,还包括一些 meta data。例如 stat 查询 inode 和 dentry 的信息,它们被存在 Linux 的 dcache 中,可以直接在内核态处理,而不需要调用 FUSE daemon 了。

2.2 User-Kernel Protocol
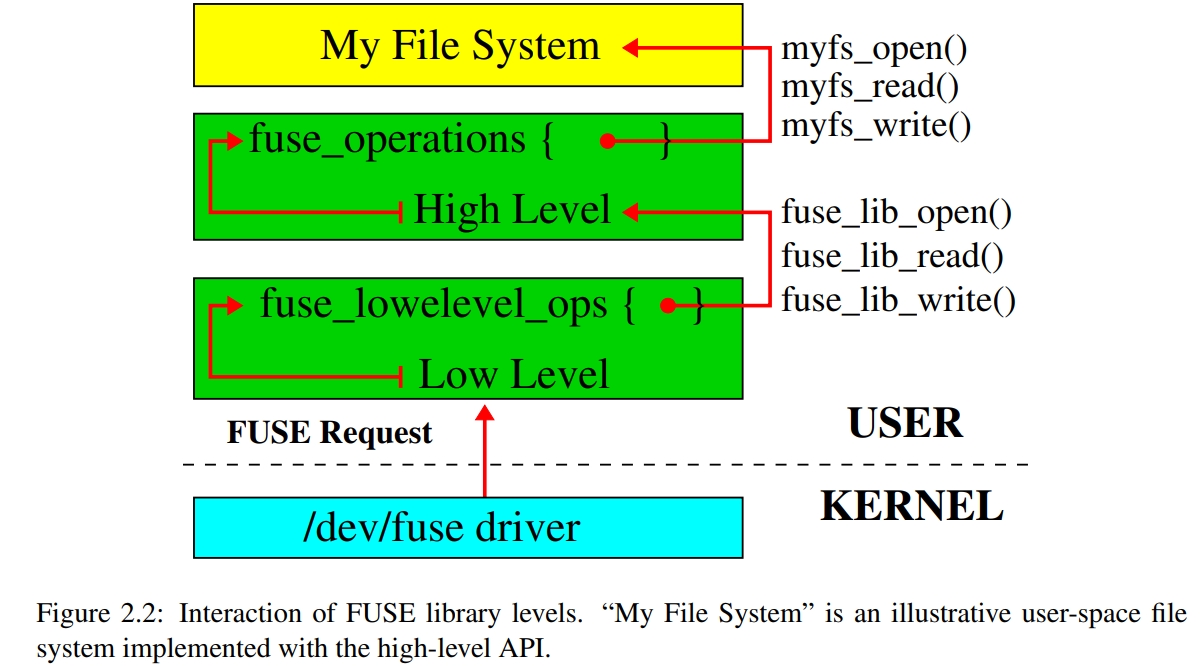
2.3 Library and API Levels
High-level 的 API 允许开发者跳过 path-to-inode 映射。或者说 inode 在 high level API 中根本不存在了,high level API 只操作路径。FORGET inode method 根本就不需要了。
无论是 high 还是 low level,反正大概都是要实现 42 个方法。
2.4 Queues
一个请求在同一时间只能属于下面五个队列的其中一个。
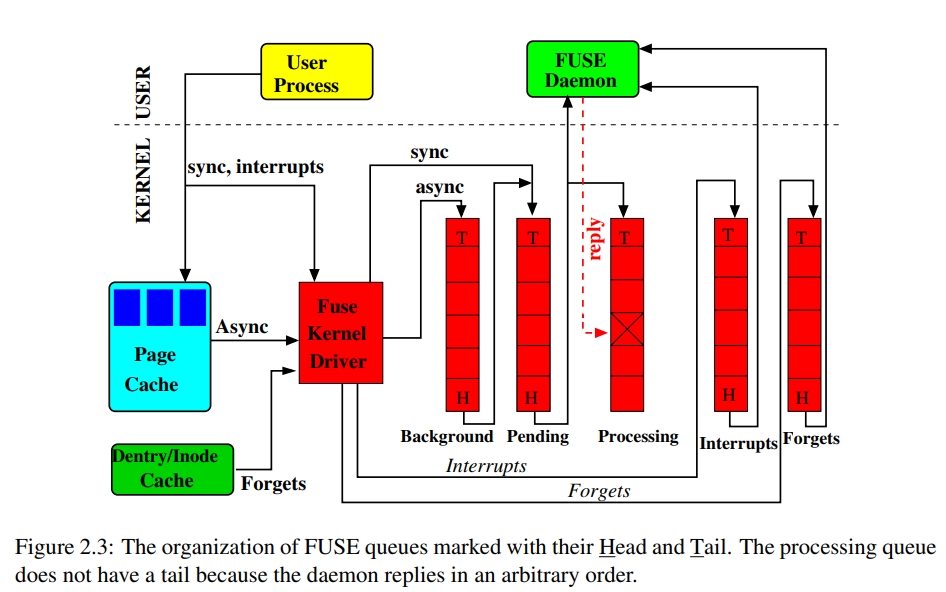
FORGET requests are sent when the inode is evicted, and these requests are would queue up together with regular file system requests, if a separate forgets queue did not exist. 如果有大量的 FORGET 请求,就无法处理其他的文件系统请求了。这个行为是在一个有 3200 万的 inode 节点上看到的,当所有的 inode 被从 icache evict 的时候,系统可能会 hang 大概 30min。
pending queue 中是同步请求。
当 daemon 从 /dev/fuse 中读取时,会以下面的顺序:
- 最高优先级会处理 Interrupts 队列中的请求
- FORGET 和非 FORGET 请求会被公平地选择,处理完 8 个非 FORGET 请求,会再处理 16 个 FORGET 请求。这也保障了 FORGET 请求不会堆积起来。
请求处理的流程是:
- pending queue 中最老的请求会被传送到 user space,然后被 processing queue 立即处理。
INTERRUPT 和 FORGET 队列并不会从 user daemon 获得回复,所以当 daemon 读取这些请求的时候,它们就终止了。 - 如果 pending queue 上没有请求,那么 FUSE daemon 就会阻塞在一个 read 调用上。
- 如果 daemon 回复了,对应的请求就会被从 processing queue 中被移除,这个请求就完成了。同时,blocked user processes (e.g., the ones waiting for READ to complete) are notified that they can proceed.
background queue 是对异步请求的。默认情况下,只有读是异步的,因为可以 read ahead。如果开启 writeback cache,则 write 也会走到 background queue 中。开启 writeback cache 后,从 user process 来的 write 会先聚集在 page cache 中,然后 bdflush 线程会醒来,去刷脏页。
background queue 中的请求会一点点汇到 pending queue 中,在 pending queue 中的异步请求的数量是根据 max_background 参数(默认 12)来调整的。目的是:
- 避免异步请求影响同步请求
- 开启 multi-threaded 选项后,限制 user daemon 线程的数量
2.5 Splicing and FUSE Buffers
在初始设置中,FUSE daemon 需要从 /dev/fuse 中读取请求,并且把回复也写到这个设备中。这样在内核和用户态之间复制内存,对 read 和 write 请求是有害的,因为通常它们会包含很多数据。因此,FUSE 会使用 Linux kernel 提供的 splice 技术。
splice() 系列的系统调用可以在两个 in-kernel memory buffer 之间传递数据,这样就不需要到用户态拷贝一次了。
例如 sendfile、mmap、splice 都是 Linux 中的零拷贝技术,主要是消除一些不需要的拷贝
FUSE 将它的 buffer 表示为下面两种形式之一:
- The regular memory region identified by a pointer in the user daemon’s address space, or
- The kernel-space memory pointed by a file descriptor of a pipe where the data resides.
If a user-space file system implements the write_buf() method (in the low-level API), then FUSE first splices the data from /dev/fuse to a Linux pipe and then passes the data directly to this method as a buffer containing a file descriptor of the pipe. FUSE splices only WRITE requests and only the ones that contain more than a single page of data.
Similar logic applies to the replies to READ requests if the read_buf() method is implemented. However, the read_buf() method is only present in the high-level API; for the low-level API, the file-system developer has to differentiate between splice and non-splice flows inside the read method itself.
下面这段话讲解了为什么 header 肯定得 copy
If the library is compiled with splice support, the kernel supports it, and appropriate commandline parameters are set, then splice() is always called for every request (including the request’s header). However, the header of every single request needs to be examined, for example to identify the request’s type and size. This examination is not possible if the FUSE buffer has only the file descriptor of a pipe where the data resides. So, for every request the header is then read from the pipe using regular read() calls (i.e., small, at most 80 bytes, memory copying is always perfomed). FUSE then splices the requested data if its size is larger than a single page (excluding the header): therefore only big writes are spliced. For reads, replies larger than two pages are spliced.
扩展
注意,上文中得到的那个 pipe,实际上是可以方便地把数据通过 pipe 的形式往下游传递的。应该是对应了第二种 buffer 的形式。
vmsplice 并不能把管道里面的数据移动到用户态内存中,所以如果需要在用户态对数据进行处理,例如需要加解密或者加解压,则得 Copy。
1 | /** Write contents of buffer to an open file |
2.6 Notifications
FUSE 可以通过回复内核的 request 向内核传递消息。但有时候,它需要主动向内核传递消息,比如 poll 调用时,如果事件发生了,FUSE 需要主动通知内核。

2.7 Multithreading
如果 pending queue 里面有多个请求,FUSE 会启动新的线程。每个线程处理一个请求,我理解这里是内核线程。处理完后,会检查是否有超过 10 个线程,如果是,则线程退出。
There is no explicit upper limit on the number of threads created by the FUSE library.
The implicit limit arises due to two factors.
- First, by default, only 12 asynchronous requests (max background parameter) can be in the pending queue at one time.
- Second, the number of synchronous requests in the pending queue is constrained by the number of user processes that submit requests.
- In addition, for every INTERRUPT and FORGET requests, a new thread is invoked.
Therefore, the total number of FUSE daemon threads is at most (12 + number of processes with outstanding I/O + number of interrupts + no of forgets).
2.8 Linux Write-back Cache and FUSE
2.8.1 Linux Page Cache
Page cache 的作用是减少 disk IO,行为是将数据存在 RAM 里面。
对于读,就是很简单的 cache。对于写,是三个策略:
- no-write 直接写 disk,invalidate cache
- write-through 写 disk 也写 cache
- write-back 只写 cache,后续异步写 disk。这些中间状态的 page 也被称为 dirty page
刷 diety page 发生在三个情况:
- free memory 低于阈值
- dirty data 比某个阈值老了
- 用户调用了 sync 或者 fsync
All of the above three tasks are performed by the group of flusher threads. First, flusher threads flush dirty data to disk when the amount of free memory in the system drops below a threshold value.
This is done by a flusher thread calling a function bdi_writeback_all, which continues to write data to disk until following two conditions are true:
- The specified number of pages has been written out; and
- The amount of free memory is above the threshold.
在 2.6 内核前,内核中有 bdflush 和 kupdated 两个线程,它们的作用和现在的 flusher 一样:
- bdflush 负责后台 writeback dirty page,当 free memory 变少的时候
- kupdated 负责周期性地 writeback dirty page
The major disadvantage in bdflush was that it consisted of one thread. This led to congestion during heavy page writeback where the single bdflush thread blocked on a single slow device.
在 2.6 内核中,引入了 pdflush 这种线程,它们会根据 io load 调整为 2 到 8 中间的数量。The pdflush threads were not associated with any specific disk, but instead they were global to all disks. The downside of pdflush was that it can easily bottleneck on congested disks, starving other devices from getting service.
Therefore, a per-spindle flushing method was introduced to improve performace. The flusher threads replaced the pdflush threads in the 2.6.32 kernel.
The 2.6.32 kernel solved this problem by enabling multiple flusher threads to exists where each thread individually flushes dirty pages to a disk, allowing different threads to flush data at different rates to different disks. This also introduced the concept of per-backing device info (BDI) structure which maintains the per-device (disk) information like dirty list, read ahead size, flags, and B.D.Mn.R and B.D.Mx.R which are discussed in the next section.
2.8.2 Page Cache Parameters
Global Background Ratio (G.B.R): The percentage of Total Available Memory filled with dirty pages at which the background kernel flusher threads wake up and start writing the dirty pages out. The processes that generate dirty pages are not throttled at this point. G.B.R can be changed by the user at /proc/sys/vm/dirty_background_ratio. By default this value is set to 10%.
Global Dirty Ratio (G.D.R): The percentage of Total Available Memory that can be filled with dirty pages before the system starts to throttle incoming writes. When the system gets to this point, all new I/O’s get blocked and the dirty data is written to disk until the amount of dirty pages in the system falls below this G.D.R. This value can be changed by the user at /proc/sys/vm/dirty ratio. By default this value is set to 20%.
Global Background Threshold (G.B.T): The absolute number of pages in the system that, when crossed, the background kernel flusher thread will start writing out the dirty data. This is obtained from the following formula:
G.B.T = T otalAvailableMemory × G.B.R
Global Dirty Threshold (G.D.T): The absolute number of pages that can be filled with dirty pages before the system starts to throttle incoming writes. This is obtained from the following formula:
G.D.T = T otalAvailableMemory × G.D.R
下面两个参数主要是限制不同设备能够使用的 page cache 的比例
BDI Min Ratio (B.Mn.R): Generally, each device is given a part of the page cache that relates to its current average write-out speed in relation to the other devices. This parameter gives the minimum percentage of the G.D.T (page cache) that is available to the file system. This value can be changed by the user at /sys/class/bdi/<bdi>/min ratio after the mount, where <bdi> is either a device number for block devices, or the value of st_dev on non-block-based file systems which set their own BDI information (e.g., a fuse file system). By default this value is set to 0%.
BDI Max Ratio (B.Mx.R): The maximum percentage of the G.D.T that can be given to the file system (100% by default). This limits the particular file system to use no more than the given percentage of the G.D.T. It is useful in situations where we want to prevent one file system from consuming all or most of the page cache.
BDI Dirty Threshold (B.D.T): The absolute number of pages that belong to write-back cache that can be allotted to a particular device. This is similar to the G.D.T but for a particular BDI device. As a system runs, B.D.T fluctuates between the lower limit (G.D.T × B.Mn.R) and the upper limit (G.D.T × B.Mx.R).
BDI Background Threshold (B.B.T): When the absolute number of pages which are a percentage of G.D.T is crossed, then the background kernel flusher thread starts writing out the data. This is similar to the G.B.T but for a particular file system using BDI. B.B.T = B.D.T × G.B.T / G.D.T
NR FILE DIRTY: The total number of pages in the system that are dirty. This parameter is incremented/decremented by the VFS (page cache).
NR WRITEBACK: The total number of pages in the system that are currently under write-back. This parameter is incremented/decremented by the VFS (page cache).
BDI RECLAIMABLE: The total number of pages belonging to all the BDI devices that are dirty. A file system that supports BDI is responsible for incrementing/decrementing the values of this parameter.
BDI WRITEBACK: The total number of pages belonging to all the BDI devices that are currently under write-back. A file system that supports BDI is responsible for incrementing/decrementing the values for this parameter.
Implementations
主要是做了一个 stackfs。
主要介绍了下面几个方面:
- inode
- lookup
- session information
主要是是每个 FUSE session/connection 的数据管理。 - directories
- file create and open
Stackfs assigns its inode the number equal to the address of the inode structure in memory (by type-casting)
也就是说,Stackfs 的 inode number 数值上是等于 inode struct 的地址的。而 FUSE 的 high level API 中,需要维护 FUSE inode number 到 inode struct 所在位置的映射关系。
Methodology
FUSE has evolved significantly over the years and added several useful optimizations: a writeback cache, zero-copy via splicing, and multi-threading. In our experience, some in the storage community tend to pre-judge FUSE’s performance—assuming it is poor—mainly due to not having enough information about the improvements FUSE has made over the years.
为了比较近年来 FUSE的优化:
- StackfsBase
- StackfsOpt -> 包含了所有的 FUSE 优化项目
- writeback cache
- 单个 FUSE 请求的最大尺寸 4KiB -> 128KiB
- user daemon 跑在 muitl-thread,也就是 fuse_session_loop_mt
- splicing is activated for all operations,应该指的是 splice 这个零拷贝技术
一些补充
FUSE 和 zero copy
如之前的图所示,FUSE 的通信模型如下。FUSE 中的一些过程是可以被 Zero-Copy 的,具体如 Splicing and FUSE Buffers 这一章节所讲的:
- WRITE 部分有限制地给超过一个 page 的数据开启 splice 功能
- READ 部分也无法避免直接读取 header
FUSE 并不能完全实现零拷贝,原因主要在需要访问 /dev/fuse。
/dev/fuse 这个设备很像是一个 rpc 调用,kernel 向它写入一些命令,例如 READ、OPEN 等,而 daemon 会从这个设备读出这些命令。daemon 会往 /dev/fuse 中写 response。
命令大概如下
1 | [ header | payload ] |
不能使用 mmap 实现 zero copy 的原因:FUSE daemon 是普通用户进程,所以在设计上就允许它 crash、被攻击、卡死等情况。而如果使用 mmap,则内核很难控制生命周期。例如当 FUSE daemon 挂掉之后,需要考虑谁来清理掉这些 mmap 的文件。
一些知识
零拷贝
Reference
- https://www.fsl.cs.sunysb.edu/docs/fuse/bharath-msthesis.pdf
完整版论文 - https://github.com/0voice/kernel_awsome_feature/blob/main/Fuse/FUSE.pdf
- https://github.com/libfuse/libfuse/blob/master/example/passthrough.c
一个最简单的 demo - https://github.com/0voice/kernel_awsome_feature/blob/main/%E8%87%AA%E5%88%B6%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F%20%E2%80%94%2003%20Go%E5%AE%9E%E6%88%98%EF%BC%9Ahello%20world%20%E7%9A%84%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F.md

