如题。
设计要点
序列化和反序列化(serde)
这里的要点,并不只局限在类似于 protobuf 的库上,而是在设计存储格式的时候,都会考虑的问题。
需要关注的 feature:
- 对于 blob 的支持
解析是否需要占用大量内存? - 读取部分数据
是否需要解压/解码全部结构,才能读取到该数据呢? - 兼容性
新旧版本应该能够处理彼此的数据。例如:- 旧版本能够忽略新增的字段,对于后续被删除的字段,也会保留其编号。
- 新版本对于旧消息中缺失的字段能补上默认值,或者填入 null。
- 类型的 cast
例如支持从 bool 升级为 enum 或者 int。 - 压缩性能
- 编码和解码的速度、CPU 开销、内存开销
这一点很重要,例如 json 的编解码性能就比较差。 - 是否可以自描述?一般出于空间考虑,这都是不包含的
- 是否有足够的容错
磁盘上的数据结构
- 磁盘 IO 的单位
- 完整性校验
- 尽可能减少 IO 次数
- 是否多个文件或者多级文件?
- 是否分开存储 meta 和 data?先写 meta 还是先写 data?
常见格式
Parquet
假设一个表中有 N 列,它们被分入了 M 个 row groups 中。那么每个 row groups 中的一个 Column 称为一个 Column Chunk。
文件的 metadata 包含了每个 Column Chunk 的开始位置。为了能够一趟写完文件,所以最后才会写入 metadata。
1 | 4-byte magic number "PAR1" |
在读取时,首先需要读取 metadata,从而定位到所有要读取的 Column Chunks。这些 Column Chunk 稍后可以被顺序读取出来。
Parquet 的格式的设计思想是将 metadata 和 data 分开,这使得可以将 Column 们分入到不同的文件中。于此同时,有一个单独的 metadata 文件去索引多个 parquet 文件。
从下面的图片中可以看到,Parquet 文件实际上是自包含的,也就是说单个 Parquet 文件已经包含完整的数据和元数据,无需依赖外部元数据文件。像 Spark 之类的系统确实会创建一个全局的 metadata 文件,但它的作用就是方便快速的索引。
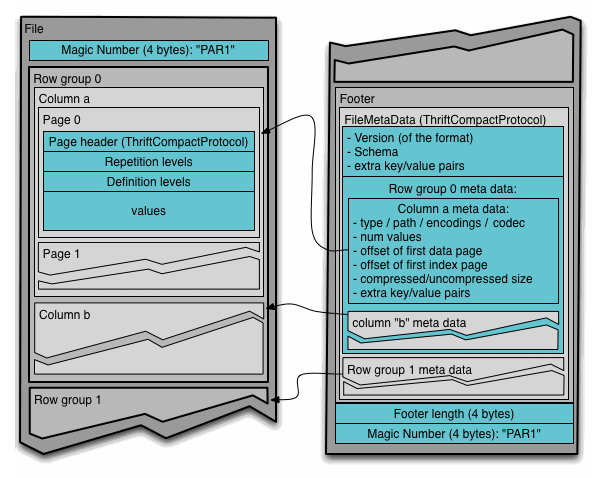
因为 metadata 在 parquet 文件的 Footer 处,所以需要先读取文件的倒数第5到8字节,得到它的大小,然后再往前 seek 这个大小解析出 metadata 部分。
Parquet 是使用 Thrift 协议解析序列化的。它和 protobuf 其实差不多,不过 Thrift 自带了 RPC。
Types
Parquet 会在 Column Chunk 层面保存 min max 值。
Nested Encoding
关于 Dremel 格式,可以看 https://paper-notes.zhjwpku.com/datalayout/dremel.html。
To encode nested columns, Parquet uses the Dremel encoding with definition and repetition levels. Definition levels specify how many optional fields in the path for the column are defined. Repetition levels specify at what repeated field in the path has the value repeated. The max definition and repetition levels can be computed from the schema (i.e. how much nesting there is). This defines the maximum number of bits required to store the levels (levels are defined for all values in the column).
Two encodings for the levels are supported BIT_PACKED and RLE. Only RLE is now used as it supersedes BIT_PACKED.
Column chunks
错误恢复
如果文件的 metadata 丢失了,那么文件损坏。如果 Column 的 metadata 丢失了,那么这个 Column Chunk 就损坏了。但是这个 Column 在其他 row group 中的部分是 OK 的。如果 page header 丢失了,那 chunk 中剩余的 page 就丢失了。如果 page 中的 data 损坏了,那么这个 page 就丢失了。
因此,如果 row group 设置的比较小,那么文件可能在 resilient 上更好。但是,这会 file metadata 更大。如果在写入 metadata 的时候出现问题,那么所有写入的数据都丢失了。一个做法是每写 N 个 row group,就写一次 metadata。每个 metadata 都是 cumulative 的,并且包含了写到现在所有的 row group。
Combining this with the strategy used for rc or avro files using sync markers, a reader could recover partially written files.

