这篇文章中,包含 Fast scans on key-value stores、PebblesDB、Snowflake。
Fast Scans on Key-Value Stores
https://vldb.org/pvldb/vol10/p1526-bocksrocker.pdf
ABSTRACT
KVS 的扩展性能好,get/put 的吞吐量大,延迟低。但是对于复杂的分析查询中,scan 的代价比较高。因为查询类型的请求需要一个很高的 locality,以及 data 的一个 compact representation。但是,弹性的 get/put 依赖 sparse indexes。
他们做了个 Tellstore,发现它的 get put 性能不差,但是分析以及混合负载的性能很好。
INTRODUCTION
KVS 的好处,相比传统数据库,除了 abstract 中提到的,还有就是它每一次读写请求的耗时是可预测的,有助于支持 SLA。
As a result, systems for analytical workloads provide additional access methods: They allow data to be fetched all at once (full table scan) and to push down selection predicates and projections to the storage layer. Most KVS do not have such capabilities and those that do, cannot execute scans with acceptable performance.
下面介绍了作者的实验。是 50M 的 YCSB Q1 在四台机器上跑。Cassandra 花了 19 分钟才跑完,非常离谱。RocksDB、MemSQL 和 Kudu 的性能能接受。注意,RocksDB 是单机数据库,所以实验是用了单个机器,跑了 1/4 的数据。但是他们相比真的 realtime,也就是 subsecond 级别,还是很遥远的。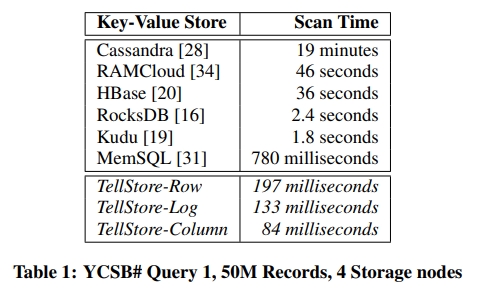
Efficient scans require a high degree of spatial locality whereas get/put requires sparse indexes. Versioning and garbage collection are additional considerations whose implementation greatly impacts performance. This paper shows that with reasonable compromises it is possible to support both workloads as well as mixed workloads in the same KVS, without copying the data.
REQUIREMENTS
SQL-over-NoSQL Architecture
下面就是作者提出的架构。Commit Manager 是用来保证 SI 的。SI 或者其他的 MVCC 实现已经成为 HTAP 的 De facto standard 因为这样 OLTP 不会和 OLAP 发生 block 或者 interfere。
下面介绍了 Commit manager 的功能,看起来类似于一个中心授时的服务,以及一个事务的仲裁机制。
With Snapshot Isolation, the commit manager simply assigns transaction timestamps and keeps track of active, committed, and aborted transactions and, thus, rarely becomes the bottleneck of the system.
这样的 SQL-over-NoSQL 架构的好处是提供了弹性。每一层中都可以独立地添加机器。比如可以快速扩容出一个 AP 节点用来做分析查询,然后查完了再删掉。
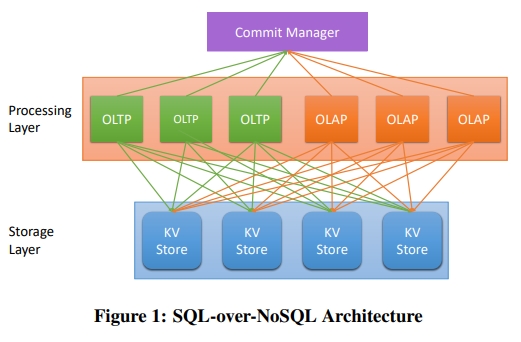
进一步精细化了这样的 SQL-over-NoSQL 需要满足的条件:
- Scans
In addition to get/put requests, the KVS must support efficient scan operations. In order to reduce communication costs, the KVS should support selections, projections, and simple aggregates so that only the relevant data for a query are shipped from the storage to the processing layer. Furthermore, support for shared scans is a big plus for many applications [38, 50, 46]. - Versioning
To support Multi-Version Concurrency Control, the KVS must maintain different versions of each record and return the right version of each record depending on the timestamp of the transaction. Versioning involves garbage collection to reclaim storage occupied by old versions of records. - Batching and Asynchronous
Communication To achieve high OLTP performance, it is critical that OLTP processing nodes batch several requests to the storage layer. This way, the cost of a roundtrip message from the processing to the storage layer is amortized for multiple concurrent transactions [30]. Furthermore, such batched requests must be executed in an asynchronous way so that the processing node can collect the next batch of requests while waiting for the previous batch of requests to the KVS to complete.
Why is it Difficult?
作者的意思是,因为上面三个条件冲突,所以很多除了 Kudu 之外的 KVS 现在都只支持点查,比如 Cassandra 或者 HBase。诸如 HBase 或者 RAMCloud 的可能还会多支持一个 Versioning,sometimes 会有 async communication。上n. All
these features are best supported with sparse data structures for get/put operations. When retrieving a specific version of a record, it is not important whether it is clustered and stored compactly with other records. 但是 scan 就对 data locality 和一个紧凑的表示有要求了。Locality 对于基于磁盘的扫描,或者只在内存中的扫描都很重要。具体来说,添加 scan 有下面的局部性冲突:
- Scan vs. Get/Put
分析系统需要列存提高 locality。KVS 喜欢行存,这样就可以在不物化 records 的情况下处理点查请求。 - Scan vs. Versioning
这个不用多说了。 - Scan vs. Batching
scan 和点查做 batch 没有什么好处。TP 负载需要低延迟,scan 的负载的延迟变化很大,取决于 predicate 以及要读取的列的数量。
DESIGN SPACE
Where to Put Updates?
主要有三种方式:
- update-in-place
大部分 rdbms 中使用。如果 records 是 fix-size 的,那么这个策略比较好,因为这样的 fragmentation 就比较少了。
如果使用了 versioning 技巧,那么就比较 trick 了。如果 version 和 record 存在一起,那么 fragmentation 就会很大,locality 就会损失。
另外一点是损失了并发性,因为更新一条记录,就需要锁住整个 page。 - log-structured
这个设计有两点好处:第一是没有 fragmentation,第二是没有 Concurrent 问题,因为 append 可以被非阻塞地实现。
它的问题是,scan 需要读取旧的数据,以及检查它们的有效性。特别地,如果 record 很少被 update,那么 gc 就比较困难。
LSM 是基于 LS 的修改,它引入了阶段性的 reorg,从而提高读取的性能。 - delta-main
最初的设计来源于 SAP Hana。也就是使用了读优化的 main,以及写优化的 delta。
How to Arrange Records?
主要是行存,或者列存。
提到了列存中的一个变体也就是 PAX。PAX 中按照行来分 Page,但是在每个 Page 中,是按照列来存的。
列存对于定长的值是性能比较好的,所以目前的系统会设法避免动态长度的值。目前的系统要么禁用,要么就是存储指针,然后将它们放在一个全局堆上面。要么就是使用字典。
How to Handle Versions?
MVCC 的两种方案:
- 在同一个地方存放一个记录的所有版本
通常和 update-in-palce 一起使用。
创建新的版本会比较简单,但是 gc 会更加麻烦,因为要 compact 这些 page。
特别地,在 LS 结构中,就需要将所有的 version 都重新拷贝到头部。 - 将所有的版本串成一个链表
更适合 LS。
但是这个指针占用额外存储。遍历这些指针会产生较多的 cache miss。
好处是这个方案下,GC 比较方便,因为它相当于是对 log 做一个 truncation。另外,这个方案的 fragmentation 较少。
When to do Garbage Collection?
两种策略:
- 在专门的线程中定期 gc
- 在 scan 的过程中 gc
其中第二种做法会增加 scan 的时间开销。但是,如果扫描频繁的表,能够被及时 gc,那么也相应能提升它们后续被扫描的性能。而且,这个时候反正数据已经再被访问了,这个时候做 gc 能够避免额外访问 data 的 cache miss。
总结
上面几点,可以最多组成 24 个设计的变体。但是其中有很多不合理的,比如 delta-main + column-major 就比 log-structured + column-major 好。另一个例子是 log-structured + chained-version 比 log-structured + clustered-versions 要好。
The two most extreme variants are the variant based on log-structured with chained-versions in a row-major format and the variant using a delta-main structure with clustered-versions in a column-major format.
下面两节中,会分别介绍 TellStore-Log 和 TellStore-Col。
TELLSTORE-LOG
这个设计是基于 RAMCloud 启发的,但是做出了重要的修改,以提升 scan 能力。
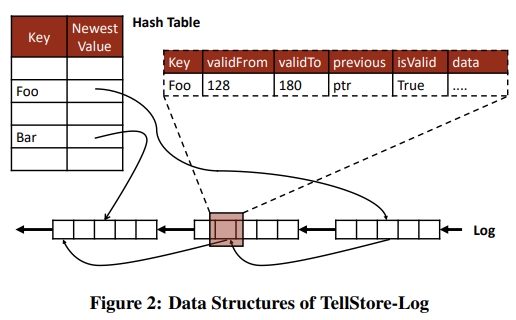
Where to Put Updates?
- Hash 表被用来索引 log 中的 record
- The log itself is segmented into a linked-list of pages storing all key-value pairs.
Memory in the log can be allocated in a lock-free way by atomically incrementing the page head pointer. 一旦一个 record 写入 log,它就是 immutable 的。因为是无锁的,所以冲突的 entry(具有相同的 key)可以被并发 append 到 log 上。一个 record 只有在它的 pointer 被成功添加到 hash table (或者被更新)之后,才被认为是 valid 的。在冲突的情况下,the record in the log will be invalidated before the data becomes immutable. Deletes are written as specially marked updates with no data.
如果 hash 表的设计是有锁了,就会是一个 contention point。很多无锁 hash table 的实现都是对某种特定访问模式的。比如,支持 resize,就会限制 lookup 和 update 的性能。TellStore 中预先分配了一个固定大小的 hash table,这个 table 被 storage node 中的所有 table 共享。这个实现使用了一个 open-addressing 算法,使用了 linear probing 机制。这样做是为了在 collision 的情况下,利用空间局部性。当然,坏处是在负载比较高的情况下,open addressing 的办法性能比较差。因此,hash bucket 中只保存 table id,record key 以及指向 record 的指针,目的是为了尽可能减少 hash 表的内存占用。
How to Arrange Records?
LS 的方法总是固有地和行存绑定。为了支持快速 scan,record 必须要 self-contained。我们特别希望避免通过查找 hash table,从而去确认一个 record 是否 valid,也就是它是否被删除了,或者被 overwritten 了。TellStore-Log 为每个 table 分配了一个 log,所以这样只会 scan 到相关的 page,提高了局部性。进一步,a scan over the log is sensible to the amount of invalid records in the log, impacting the locality requirement, as we will see in Section 4.4.
How to Handle Versions
为了找到一个 key 的较老版本,需要维护一个 version-chain。也就是每个 reocrd 都会存一个自己的 previous pointer。另外,the timestamp of the transaction creating the record 会被存放在一个 valid-from 字段中(放在 metadata 里面)。This version chain is always strictly ordered from newest to oldest according to the snapshot timestamp, with the hash table pointing to the newest element. 给定一个 snapshot timestamp,一个 get 操作能够遍历这个 chain,从而找到第一个满足的元素。这个操作有大量的 cache miss,但是这是实现快速写入的代价。
看起来,这个设计似乎是和 self-contained 这个要求冲突的,如果只能提供 creation timestamp,那么 scan 的时候就不能确定一个 record 是否已经过期了。因此,为了避免查 hash table,就需要添加一个 valid-to timestamp 表示什么时候过期。这是一个 mutable 字段,也存放在每个 record 的 metadata 里面。当成功写入了一个对象 record 的一个新版本之后,前一个版本的 valid-to 就会被设置为新版本的 valid-from。Given a snapshot timestamp, the scan can decide if an element qualifies for inclusion in the snapshot only by comparing the two timestamps.
The hash table remains the sole point of synchronization and always points to the newest element. There is no race-condition between updating the hash table and setting the valid-to field, as Snapshot Isolation in TellStore does not guarantee visibility for inprogress transactions.
When to do Garbage Collection?
scan 的性能,受到有多少过期了的 element 的影响。
对于每一个 page,根据 size 计算一个 valid rate。如果这个值低于某个特定的阈值,page 就会被 gc。也就是在下一次扫描的时候,会被重写。重写是拷贝剩余的 active 的 element 到 log 的头部。不需要的 page 会被返回给 free page pool 复用。当拷贝完新的 log head 之后,这个 key 的 version chain 的 pointer 需要被调整。也就是说,需要在 hash table 中查找这个 key,然后找到 version chain 的对应位置。显然,这个操作代价昂贵,因为空间局部性差。
总结
这里的主要贡献是提供了一个办法去让 log record 能够 self-contained,这样 MVCC 遍历会更快。另外,它提出 hash table 的内存使用要减少,因为即使 concurrent hash table 也是有 drawback 的。
TELLSTORE-COL
如下图所示,包含四个结构:
- 一些 page 用来储存 main 的数据
- 两个 log 用来保存 delta,一个存 inserts 一个存 updates
1, 一个 hash table 用来索引数据
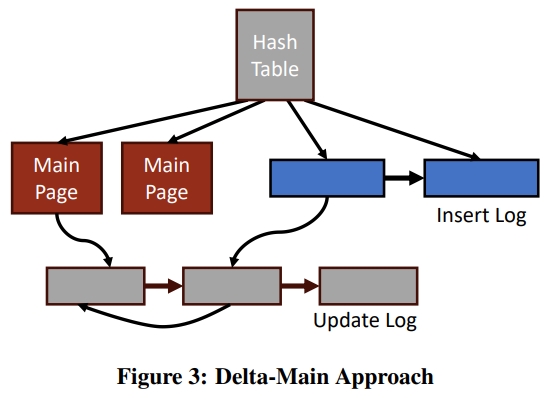
Where to Put Updates?
Except for select metadata fields, main 中的数据是制度的,所有的更新会被写到一个 append-only 的 LS 存储中。不同于 TS-Log,delta 存在两个 log 里面,分别是 update-log 和 insert-log。作这个区分的好处是可以更容易从 delta 构建 main。在 index 中存了一个 flag,表示这个 pointer 指向的是 delta 还是 main。除了这个 flag 之外,index 和 TS-Log 使用了相同的 hash table。
在写之前,需要查询 index,寻找 record 的 key。如果这个 key 不存在,就插入到 insert-log。这是因为在 LS 的方法中,冲突的 entry 是可以被并发写到 log 中的。对于插入,index 部分是一个 point of synchronization,只有在将一个 pointer 插入到 index 中之后,这个 insert 才是有效的。
如果 key 是存在的,record 就会被 append 到 update-log 尾部。在 main 和 insert-log 中的 record 中都有一个可变的 newest 的字段,它保存了一个指向同一个 key 的最新被写入的元素。
【Q】从图中可以看出,这是在说 main 和 insert-log 中的每个 key,都会有一个指针 newest 去指向 update-log 中的一个位置,表示这个 key 中最新的数据。所以我理解这个指针的更新会有比较昂贵的开销。
同样,冲突的 records 可以被并发地写到这个 log中。这个 newest pointer 是 update 的 point of synchronization。
How to Arrange Records?
对于两种 delta-log,它们都是以行存进行存储的。但是对于 main,则可以讨论具体的存储方式。
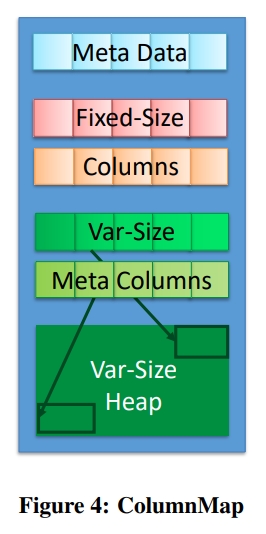
TS-Col 中使用一个列存,称为 ColumnMap 的方式存储 main。这个思想实际上类似 PAX。
如果一个 table 中的每个 field 都是 fixed size,那么就足以知道一个 record 的 first attribute 出现的位置。这个位置可以通过 page 中有多少个 record,以及每个 attribute 的 data type size 来计算出来。但是如果 fields 中有可变长度的类型,那么就不能这么简单计算了。
所以,如下图所示,除开了 Fixed Size Columns 之外,有一个 heap 用来存储所有的可变长度的字段。This heap is indexed by fixed-size metadata storing the 4-byte offset into the heap and its 4-byte prefix. While the metadata fields are stored in column-major format, the contents of the fields are stored in row-major format in the heap.
这有两个好处。首先,当物化 records 的时候,变长的 fields 已经是以行存格式存在的了,所以可以被简单拷贝到 output buffer 中。其次,在 fixed-size column-major format 中保存一个前缀,可以加快通常的基于前缀的 scan queries。这是因为我们可以根据前缀,去缩小需要选择的 tuple 的反而,减少查询 heap 的次数。
How to Handle Versions?
TS-Log 同样也保存了 valid-from,作为 records 的 metadata 的一部分。在 update-log 中的 records 会被从新到旧地连接起来,每个版本都会持有一个 previous pointer。在 main 和 insert-log 中会存储的 newest pointer 会指向 update-log 中的最新的元素。为了避免 loops,没有从 update-log 到 main 的 back pointer。
在一个 main page 中,同一个 key 的不同版本会被连续地从新到旧地存放在一个 column-major format 中。valid-from 时间戳,和 newest pointer 也会被转成 column-major 的格式,并且在 metadata scetion 中以 normal attributes 的形式进行存储。index 总是指向 the metadata field of the newest element in the ColumnMap or the insert log. 给定一个 snapshot timestamp,会从新到旧开始扫描 valid-from 字段,直到 a timestamp is found that is contained in the snapshot.
和之前原理相同,为了保证 record 是 self-contained 的,需要将 newest pointer 和 record 一同存储,而不是存在 hash table 中。否则,为了知道一个 new record 有没有被写入过,就必须查找 hash table 了。Records in both delta-logs only store the timestamp of the transaction that created them and as such are not self-contained. This is a trade-off between scan and garbage collection performance, as discussed in Section 5.4.
When to do Garbage Collection?
GC 主要负责定期将两个 delta-logs 中的更新 merge 到 main 中。这能保障有效率的 scan 需要的局部性。所有的 main page 都是不可变的,并且通过 COW 机制去 rewrite。This is necessary in order to not interfere with concurrent access from get/put and scans, as update-in-place would require a latch on the page.
相比 TS-Log,从 delta 到 main 去 compact page 是更加昂贵的,因为涉及行转列。所以,GC 会作为一个单独的线程来运行,而不会被 piggy-back 到 scan 过程中。这个专门的线程会定期扫描 main 中每个 page 的 metadata 部分,一旦它发现一个 page 中有某个 record,它要么被 update 了(通过检查 newest 指针),要么不在被任何 active 的 snapshot 持有(通过检查 valid-from 字段),就会重写这个 page。
通过遍历 version chain,可以从 main 和 update-log 中得到这个 key 的所有的 version。 Elements with timestamp that are not contained in any active snapshot are discarded, while elements gathered from the update-log are converted to column-major format. 所有这些元素,会被从新到旧排序,然后被 append 到一个新的 main page 中。在 relocate 一个 record 之后,newest 字段会被更新,指向 new record。这样并发的 update 能够知道发生了这个 relocation。最后,GC 会扫描所有 insert-log 中的 record,将 update-log 中所有这个 key 的写入取出来,并且以列式写到 main page 中。此后,delta-logs 可以被 truncated 掉,然后这些旧的 page 会被放到 free page 池中。
通过分离 insert 和 update log,GC 只需要扫描 insert-log 从而获取所有不在 main 中的 key。当然,坏处是,它会降低 scan 的数据局部性,因为 update 会导致 scan 为了遍历 version chain 从而去从 update-log 中随机读取。这里的前提是让 GC 更加有效率,这样它能更频繁地跑,从而减少 update-log 的大小。
Page 是被 aggressively 进行 compact 的。如果一个 page 中的一个 element 变为 invalid 了,整个 page 就会被 rewrite。如果负载比较中,那么写放大就会比较大。这对 dick-based 系统影响比较大,但是 memory-based 的系统就还好。An extension to this approach would be to compact pages based on dirtiness, similar to TellStore-Log. Delaying the compaction, on the other hand, will keep a higher portion of the data in the delta-log which, in turn, will impact scan performance.
Summary
Versioning can be achieved by clustering records of the same key together and treating their timestamp as a regular field in a column-major format.
IMPLEMENTATION
Asynchronous Communication
意思是等待 storage request 被完成的时候,processing instance 不要闲置。所以用了叫 InfinIO 的这个异步通信库。 InfinIO, which was built specifically to run on top of Infiniband, employs user-level threads and callback functions through an API similar to the one provided by Boost.Asio for Ethernet communication. All requests to TellStore immediately return a future object on which the calling user-level thread can wait.
InfinIO then transparently batches all requests at the network layer before actually sending them to TellStore. Likewise, responses from the storage are batched together before sending them back to the processing nodes. This batching greatly improves the overall performance as it cuts down the message rate on the Infiniband link, which would otherwise become the performance bottleneck.
Thread Model
如下所示,分为了下面几种类型的线程。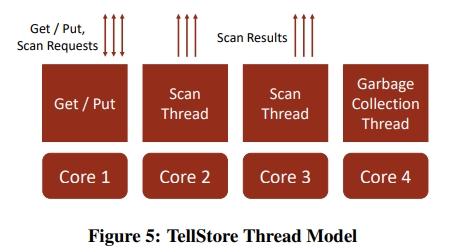
To guarantee a consistent throughput for scans and get/put operations, TellStore only uses lock-free data structures.
有一个 scan 线程还扮演 scan coordinator 的角色。它会将队列里面的所有 scan request 组合成一个 single shared scan。 The coordinator partitions the storage engine’s set of pages and distributes them equally among the scan threads. All the scan threads (including the coordinator) then process their partition in parallel independently. 每一部分的结果会通过 RDMA 被直接写到 client 的内存中。
Data Indexing
在 TS-Log 和 TS-Col 的介绍中,讲解了使用一个 lock-free hash table 去在单个 node 中索引 records。为了在多个 nodes 中索引 keys,TS 实现了一个类似 Chord 的分布式 hash table。如何选择 hash table 是和如何支持快速 scan 正交的一个问题。
对于 range partitioning,可以使用像 Btree 或者 LSM 去在 page 内索引数据。但这会让 get/put 操作更加昂贵。为了支持 range query,Tell uses a lock-free B-tree that is solely implemented in the processing layer as described in [30].
Predicate Pushdown
PebblesDB
https://www.cs.utexas.edu/~vijay/papers/sosp17-pebblesdb.pdf
摘要
本文提出了一个 Fragmented LSM 降低 LSM 的写放大和内存开销。FLSM 引入了一个叫 guard 的概念来组织 logs,避免在同一层中 rewrite data。通过修改 HyperLevelDB 的代码,来实现 FLSM 的数据结构。测试显示,PebblesDB 能够减少 2.4-3 倍的写放大,提升写吞吐量为 6.7x。
INTRODUCTION
下图是常见的 kvstore 的写放大。在测试中使用了 500M 个 kv 对,并且它们被随机 insert 或者 update。通常的思考是,减少写放大通常需要牺牲 write 或者 read 的吞吐量。在当前的低延迟、大写入的场景中,用户并不愿意牺牲任何一个。
LSM 的写放大的问题主要是数据结构本生。因为 LSM 要求 sorted order,从而支持高效率的查询。但是当新的 data 被添加到 LSM 中,就需要 rewrite 既有的数据,从而导致大量的 write IO。
主要贡献:
- 提出了 FLSM 树,将跳表和 LSM 树结合。
- 实现了 PebblesDB
- 实验结果
BACKGROUND
Log-Structured Merge Trees
Write Amplification: Root Cause
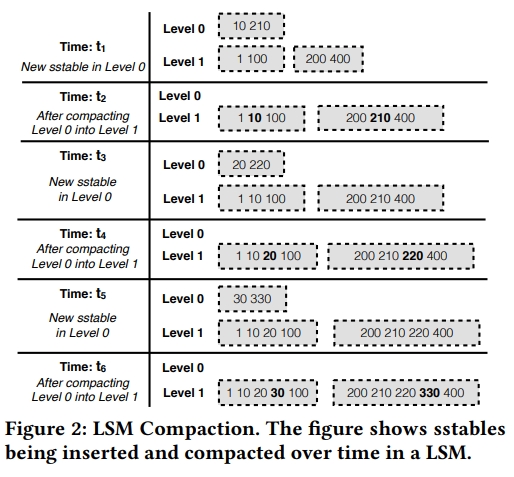
下图展示了 LSM KVStore 中的 compaction。Level 1 中最初有两个 sst。假设 Level 0 被配置为最多只能有一个 sst,当达到 limit 之后,compaction 就会发生。在 t1 时刻,添加了一个新的 sst。在 t2 时刻,触发了一个 compaction。后面的 3-6 也是同理的。在 compact 一个 sst 的时候,所有下一层中 range 和这个 sst 相交的都会被 rewrite。在这个例子中,因为 level 0 中的所有 sst 都和 level 1 中的 sst 相交,所以只要 level 0 被 compact 了,level 1 就需要被重写。在这个最坏的情况的例子中,Level 1 sstables are rewritten three times while compacting a single upper level.
The Challenge
一个减少写放大的做法就是不去 merge sst,而是直接加 sst。但这样会导致 read 和 range query 的性能显著降低。因为:
- 如果不 merge,那么 kvstore 中就会存在大量 sst
- 因为现在有多个 sst 中包含相同的 key,并且相同的 level 上有 overlap 的 key range,读操作需要访问较多的 sst
FRAGMENTED LOG-STRUCTURED MERGE TREES
目的是同时达到:低写放大、高写吞吐、好的读取性能。
FLSM 可以看做是 LSM + SkipList,以及一个新颖的可以减少写放大和增加写吞吐的压缩算法。lsm 的基础问题是 sst 会被重写多次。m. FLSM counters this by fragmenting sstables into smaller units. 现在相比重写 sst,FSLM 的 compaction 只是会将一个新的 sst fragment 去 append 到下一层中。这就保证了数据在大多数层中只会写最多一次。对于较高的层,会用一个不同的 compaction 算法。
FLSM 通过 guards 去实现这个 lauour。
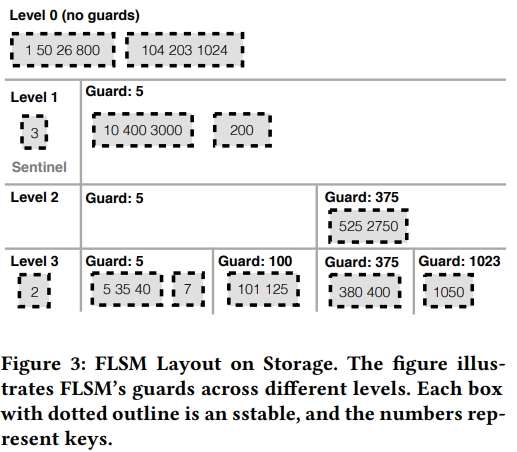
Guards
在传统的 lsm 中,每一层包含的 sst 对应的 key range 都是不相交的,也就是说每个 key 都只会在一个 sst 中出现。本文的主要观察是为了维护这个 invariant,是导致写放大的根因,因为它强迫同一层中的数据被重写。FLSM 放弃了这个 invariant,也就是每一层中可以包含多个 overlap 的 sst,也就是说一个 key 可能在多个 sst 中。为了方便从每一层中找到 key,FLSM 将 sst 组织乘了 guards。
每一层中包含多个 guards。Guards 将 key space 分成了不相交的单元。每一个 guard Gi 有一个关联的 key Ki,是从被添加到 FLSM 的 key 中选择的。层数越高,guards 越多,也就是当数据被 push 到越来越低的层的时候,guards 就会显著变多。和 skip list 一样,如果一个 key 是 i 层的 guard,那么它也是所有 level > i 的层的 guard。
每一个 guard 有一系列关联的 sst。每个 sst 都是 sorted 的。如果 guard Gi 和 Ki 关联,guard Gi+1 和 Ki+1 关联,那么在 [Ki, Ki+1) 中的 sst 就会被 attach 到 Gi。每一层中比第一个 guard 小的 sst 会被一个专门的 sentinel guard 来存储。最后一个 guard Gn 会存储所有 keys 大于等于 Kn 的 sst。一层中的 guard 不会有 overlap 的 key range。
在 FLSM compaction 的实现中,the sstables of a given guard are (merge) sorted and then fragmented (partitioned), so that each child guard receives a new sstable that fits into the key range of that child guard in the next level.
下图中是一个例子。
- put() 会导致 key 被添加到 memtable 中。最终 memtable 会变慢,那么会被 dump 为 level 0 层的一个 sst。level 0 没有任何的 guards。
- 当层数变高,guards 的数量就会变大,但并不一定是指数级别的变大。
- 每一层都有个 sentinel guard。
- 在 FLSM 中的数据是被部分排序的
Selecting Guards
Guard Probability
用 guard probablity 定义一个 key 是否是 guard。即 gp(key, i) 表示 key 是第 i 层的 guard 的概率。level 1 的 guard 是最少的,所以 gp 就很低。随着 level 的增高而增高。
如果 K 是第 i 层的 guard,那么它也是第 i + 1、i + 2 等的 guard。
Other schemes for selecting guards
FLSM could potentially select new guards for each level at compaction time such that sstable partitions are minimized; however, this could introduce skew. We leave exploring alternative selection schemes for future work.
Inserting and Deleting Guards
guards 不是同步地被插入 FLSM 中的。因为插入 FLSM 中需要切分或者移动 sstable。如果一个 guard 被插入到了多个 level 中,那么就需要要对所有层进行处理。因此,作者将它设计为并行的。
当 guards 被选中,他们会被插入到一个内存中的 set 中,称为 uncommitted guards。sstable 并不会基于这些 uncommitted guards 而进行划分。
在下一次的 compaction cycle 中,sstable 会被旧的 guard 以及 uncommitted guard 重新划分。任何需要被 uncommitted guard 切分的 sstable 会被 compact 到下一层中。在 compaction 的最后,uncommitted guards 会被持久化到存储中,并被加到 guards 的集合中。后续的读取都会基于这个全集来做了。
在大部分的 workload 中,删除 guard 都是不必要的。一个 guard 可能因为 key 被删除了,所以变为空的。但这并不影响性能,因为 get() 会跳过这些空的 guards。当然,有两个场景删除是有用的:
- guard 是空的
- 这一层中的数据在 guard 中分布是不均匀的。此时,重新计算 guard 能够提升性能。
删除 guard 这个行为也是异步做的。也有一个内存中的 set 来维护 uncommitted 的删除。删除 G 这个 guard 会导致所有属于 G 的 sst 被重新添加到 level i 的相邻分区,或者 level i+1 中。注意,从 level i 到 i + 1 的 compaction 是正常的,因为 G 依然是 level + 1 的一个 guard。
FLSM Operations
get
首先找 memtable,如果找不到,从 level 0 开始找。
这里最坏的情况是每一层都需要读一个 guard,然后这个 guard 里面的每个 sst 都需要被读取。
range query
首先需要确定每一层涉及到的 guard。对每个 sst 执行一次二分查找,找到最小的 key,后面的 key 就通过类似于 merge 的方式来处理了。
put
略
key updates and deletions
也是通过 sequence number 来维护版本的。
compaction
当一个 guard 中的 sst 数量到达阈值之后,就会 compact 到下一个 level。【Q】所以看起来 compaction 的粒度是 guard 了。
The sstables in the guard are first (merge) sorted and then partitioned into new sstables based on the guards of the next level; the new sstables are then attached to the correct guards. For example, assume a guard at Level 1 contains keys {1, 20, 45, 101, 245}. If the next level has guards 1, 40, and 200, the sstable will be partitioned into three sstables containing {1, 20}, {45, 101}, and {245} and attached to guards 1, 40, and 200 respectively.
大多数情况,compaction 都不需要 rewrite sst。这是 FLSM 如何减少写放大的 main insight。【Q】但这里 split 一个 sst 应该也是需要重写的?新的 sst 会被简单地直接加入到下一层中的对应 guard 中。但是有两个例外:
- 对于最高层,也就是 level 5,sst 需要在 compaction 的时候重写。显然没有更高的层可以给它继续放了。
- 对于次高层,也就是 level 4,FLSM will rewrite an sstable into the same level if the alternative is to merge into a large sstable in the highest level (since we cannot attach new sstables in the last level if the guard is full)
The exact heuristic is rewrite in second highest-level if merge causes 25× more IO.
FLSM 的 compaction 是可以并行的。因为 compact 一个 guard 只涉及到下一层中的对应的 guard 们。FLSM 中选择 guards 的方法保证了 compact 一个 guard 的同时不会影响到同一层中的其他 guard。
Tuning FLSM
Tuning max_sstables_per_guard allows the user to tradeoff more write IO (due to more compaction) for lower read and range query latencies. Interestingly, if this parameter is set to one, FLSM behaves like LSM and obtains similar read and write performance. Thus, FLSM can be viewed as a generalization of the LSM data structure.
Limitations
get 以及范围查询,因为要检查 guard 中的所有的 sst,所以读取的延迟增加了。
Snowflake
https://dl.acm.org/doi/pdf/10.1145/2882903.2903741
ABSTRACT
这里强调就是性价比高,性价比高的原因是弹性做得更好,比如使用了 serverless 的架构。另外,snowflake 也更云原生。
INTRODUCTION
现在平台变了,上云了。上云主要就是 scalability 和 availablility 和 pay-as-you-go 的 cost model。
不仅平台变了,数据也变了。现在数据更加 schema-less 或者 semi-structured。
Hadoop 或者 Spark 这样的大数据平台缺少 much of the efficientcy and feature set of established data warehousing technology。
- Pure Software-as-a-Service (SaaS) Experience
- Relational
- Semi-structured 提供一些内置的函数和 SQL 扩展,方便对 semi-structured 的数据进行遍历、flattening、nesting。支持 JSON 和 Avro。列存以及 automatic schema discovery 的技术让这样的数据也能和关系数据一样处理起来很快。
- Elastic
- Highly Available
- Durable
- Cost-efficient
- Secure
SNowflake 在 AWS 上运行,但是也能够被 port 到其他的平台上。
STORAGE VERSUS COMPUTE
Share-nothing 系统能够成为主流的数仓,主要是因为 scalability 以及 commodity hardware。在这种架构下,每一个 query processor 都有自己的本地磁盘。表被水平 partition。这样的架构对 star-schema 的查询是比较好的,因为 very little bandwidth is required to join a small (broadcast) dimension table with a large (partitioned) fact table. 因为共享数据结构或者硬件之间的竞争很少,所以不需要很昂贵的硬件。
Snowflake 认为纯粹的 shared-nothing 架构将存储和计算绑定在一起,从而导致问题,场景有:
- Heterogeneous Workload
bulk loading 是高 IO 带宽,低 CPU 开销;相比复杂查询是 CPU 需求高的。这样的异构负载,但是我们的节点又是同构的。 - Membership Changes
这里主要负担是要 shuffle 一堆数据。
可以通过 replication 来缓解这个问题。 - Online Upgrade
然后,云上环境这三点都是很正常的。
出于上述考虑,Snowflake 进行了存算分离。Compute 是专有硬件的 shared-nothing 架构的引擎。Storage 是在 S3 上提供的,虽然实际上任何 blob 存储都是满足要求的。为了减少网络传输,Compute node 会在本地磁盘上存储一些表的数据。
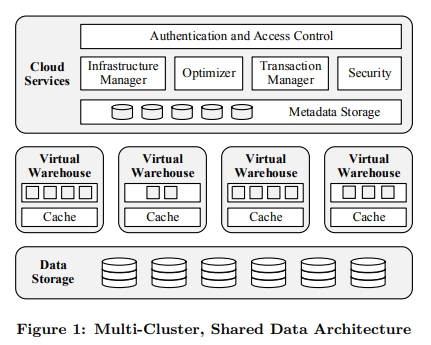
Snowflake 将这种架构称为 multi-cluster、shared-data 架构。
ARCHITECTURE
Snowflake 的三层架构:
- Data Storage
- Virtual Warehouses
- Clous Services
Data Storage
选择 AWS 的原因:
- AWS 最成熟
- AWS 上的潜在用户最多
第二个选择是直接使用 S3 还是用一个自己基于 HDFS 研发的自有存储服务。Snowflake 的经验是,S3 的性能会变动,但是可用性、以及 durability 是很强的。所以选择 S3,然后主要精力用来研究 VW layer 中的 local caching 和 skew resilience 技术。
S3 相比本地磁盘,延迟是高很多的,并且每一个 IO 请求的 CPU 开销也大很多,特别是使用 HTTPS 请求。但最关键的是,S3 上文件只能够被 write/overwrite in full。我们甚至无法在一个文件末尾去 append 数据。实际上我们需要在 PUT 的时候,就声明文件的大小。BTW,S3 支持读文件的一部分。
一张表被分成很多个不可变的大文件。每个文件使用 PAX 格式存储。每个表文件中包含一个 header,记录了文件中每个 column 的 offset。所以只需要下载 metadata,以及感兴趣的 columns。
Snowflake 也是用 S3 存储被 query operator 生成的临时文件,比如和 join 相关的临时结果。当然,一般这发生在本地磁盘被耗尽的情况。这样,就能处理 OOM 或者 out of disk 的情况。
Metadata,这里值 catalog 对象、事务日志、锁等,被存放在一个 KVStore 里面。这个 KVStore 属于最上层的 Cloud Service。
Virtual Warehouses
这一层中是 EC2 集群。它们会以一个 virtual warehouse 即 VW 的抽象的方式暴露给单个用户。VW 中的单个 EC2 节点成为 worker node。用户并不会直接和 worker node 交互,也不关心 VW 具体实现的细节。实际上,会像 AWS 一样提供不同型号的 VW 的抽象供用户选择。这部分的设计实际上很 cloud native。
Elasticity and Isolation
在没有查询的时候,用户可以关闭所有的 VW。单个查询运行在单个 VW 上面,worker node 也不会跨 VW 共享。从好的方面来讲,这导致每个查询的 performance isolation 很好。从坏的方面来讲,利用率可能就不高了。
所以当一个新的查询被提交的时候,VW 中的全部,或者部分(如果查询比较小的话)work nodes 会各自创建一个全新的 worker process。每个 worker process 的生命周期是整个 query。
每个用户可能同时有多个 VW 在运行,每个 VW 也可能运行多个并发的查询。每个 VW 都访问同一份 shared tables。
Shared, infinite storage means users can share and integrate all their data, one of the core principles of data warehousing.
Another important observation related to elasticity is that it is often possible to achieve much better performance for roughly the same price. For example, a data load which takes 15 hours on a system with 4 nodes might take only 2 hours with 32 nodes
Local Caching and File Stealing
每个 worker node 会在本地磁盘上存储 S3 的一些表文件的元数据,以及一些需要用到的列。这个 cache 的生命周期和 worker node 一致,并且被上面的多个 concurrent 或者 subsequent 的 worker process 共享。有一个 LRU 策略用来 evict 这些 cache。
进一步,每个查询会对需要读的表的 table id 做一致性哈希,这样访问相同表的查询都会集中到相同 worker node 上,从而减少冗余的 cache。
一致性哈希是 lazy 进行的,也就是说,当 worker nodes 配置变更时,data 不会立即被 shuffle。相反地,Snowflake 借助于 LRU cache 去最终替换 cache 的内容。这摊还掉了 the cost of replacing cache contents over multiple queries.
【Q】这里 TiFlash 是通过 Region 信息找到存有副本的实例,从而去读取对应实例的 S3 来解决问题的。
此外,还需要解决 skew 的问题,也就是一些节点会运行地显著比其他节点慢。所以有一个 file stealing 策略,当一个节点完成自己的任务后,它会尝试向它的 peer 去请求额外的文件。它会直接从 S3 下载文件,以避免给那个 peer 带来额外的进一步的负担。
Execution Engine
首先,如果能用 10 个 node 跑完的任务,就不需要用 1000 个 node 来跑了。所以尽管 scalability 很重要,但是每个节点本身的效率也是很重要的。
Snowflake 的执行引擎是 Columnar、Vectorized、Push-based 的。Vectorized 这里指的也是 late materialzation。
一些传统事务中存在的问题,在 Snowflake 中不需要处理。
- 首先,执行的时候不需要处理事务管理,因为查询只会读取一些列不可变的文件。
- 然后,没有 buffer pool。因为大部分查询会扫描大量的数据。在内存中 cache 这些结果是一个很不好的实践。
【Q】但是 Cache 所需要的列,特别是解压后的结果,以避免重复解压的开销是很重要的。
Cloud Services
VW 是 ephemeral 的,用户特定的资源。但是 Cloud Service 层是 multi tenant 的。这一层中有 access control、query optimizer、transaction manager 以及其他的服务,它们都是常驻的,并且被所有用户共同分享。多租户能够有效地提升利用率。
Query Management and Optimization
Concurrency Control
也是基于 SI 的 ACID 事务模型。在 SI 下,所有的读看到的是事务开始的时候的一致性视图。SI 基于 MVCC 实现。MVCC 也是因为基于 S3 后,文件都得是 immutable 的。
Pruning
这里将如何做到只扫描需要的一部分数据。传统数据库中,通常使用索引做到这一点。Snowflake 不是很适合的原因是:
- 索引很依赖随机访问,对于压缩的格式,以及 S3,都不是很友好。
- 维护一个索引,会增加数据的大小,以及数据被加载的时间。
- 用户需要显式创建索引,这个和 Snowflake 的设计精神不是很契合。
一个替代的做法是 min-max 索引,也被称为 small materialized aggregates、zone maps 或者 data skipping。这个方案是对于每个 chunk,都记录了它上面的最大值和最小值。
Snowflake keeps pruning-related metadata for every individual table file. The metadata not only covers plain relational columns, but also a selection of auto-detected columns inside of semi-structured data, see Section 4.3.2.
The optimizer performs pruning not only for simple base-value predicates, but also for more complex expressions such as WEEKDAY(orderdate) IN (6, 7).
Besides this static pruning, Snowflake also performs dynamic pruning during execution. For example, as part of hash join processing, Snowflake collects statistics on the distribution of join keys in the build-side records. This information is then pushed to the probe side and used to filter and possibly skip entire files on the probe side. This is in addition to other well-known techniques such as bloom joins.
FEATURE HIGHLIGHTS
Pure Software-as-a-Service Experience
Continuous Availability
Fault Resilience
Online Upgrade
Semi-Structured and Schema-Less Data
支持 VARIANT 类型。从而实现 “schema later” 模式:相比于 ETL,它把这个叫做 ELT。也就是在加载输入的时候,并不需要指定 schema,无论是从 JSON、Avro 还是 XML 格式去加载。
ELT 的好处是,如果后续数据需要被转换,就可以利用这个数据库本身来执行。Snowflake 支持基于 js 去定义 UDF。
Post-relational Operations
Columnar Storage and Processing
As mentioned in Section 3.1, Snowflake stores data in a hybrid columnar format. When storing semi-structured data, the system automatically performs statistical analysis of the collection of documents within a single table file, to perform automatic type inference and to determine which (typed) paths are frequently common. The corresponding columns are then removed from the documents and stored separately, using the same compressed columnar format as native relational data. For these columns, Snowflake even computes materialized aggregates for use by pruning (cf. Section 3.3.3), as with plain relational data.
Optimistic Conversion
有一些 native 的 SQL 类型,例如时间日期会在外部格式,比如 JSON 或者 XML 中以字符串的形式保存。这些值会在 write 或者 read 的时候,被重新转换成实际的类型。
如果在 read 的时候进行转换,通常会花费很多 CPU。此外,这会导致之前说的 pruning 无法执行,这特别是对日期类型。
但是在 write 的时候进行转换,会丢失信息。例如,00000000010 不一定表示 10,他也可能就是一个有很多前导 0 的字符串。或者,一个像日期的数实际上是电话号码。
Snowflake 会使用乐观转换的办法。也就是同时保留转换后的列,以及转换前的列。因为在读取的时候,要么读转换后的,要么读转换前的,所以不会有读两次的开销。
Performance
Time Travel and Cloning
CLONE 操作就是类似于 COW 一样。

