这篇文章中,包含 Column Stores vs Row Stores、To BLOB or Not To BLOB: Large Object Storage in a Database or a Filesystem?、Cloud Programming Simplified: A Berkeley View on Serverless Computing。
Column-Stores vs. Row-Stores: How Different Are They Really?
主要是说,列存和行存在 query execution level 和 storage level 上的不一样导致了难以用行存模拟列存。
INTRODUCTION
尝试回答下面这个问题:
Are these performance gains due to something fundamental about the way column-oriented DBMSs are internally architected, or would such gains also be possible in a conventional system that used a more column-oriented physical design?
下面这些技术尝试用在行存上,看能不能让它 as “column-oriented” as possible.
- Vertically partitioning。将表切分成一系列 two-column table,这个 table 由 (table key, attribute) 对们构成。所以只有需要的 column 会被 query 所读取。
- index-only plan。创建一系列的 index,足以覆盖查询中所有被用到的 column。这样就根本不用查下层的行存表了。
- 用一系列物化视图,使得每个查询所需要的列,都能够有一个对应的视图,虽然这个方案要用很多的空间,但是对 row store 来说是一个 best case。
论文应用了这些优化,然后以 CStore 作为基线来对比,使用 SSBM 负载。结果显示,尽管上面的这些方案都在行存中模拟了列存,但是 query processing performance 依然是很差。
下一个问题是:
Which of the many column-database specific optimizations proposed in the literature are most responsible for the significant performance advantage of column-stores over row-stores on warehouse workloads?
这里,作者列出了这些 column-database specific optimizations:
- 延迟物化。这里还需要和下面的 block iteraton 结合起来。
- Block iteration。这个技术也被称为 vectorized query processing。这里指从一个列中读到的多个 value,以一个 block 的方式从一个 operator 传到另一个。和这个相对应的是类似于 Volcano 一样的 per-tuple iterator。如果 value 是 fixed width 的,它们会被像一个 array 一样被遍历。
- Column-specific 的压缩方式。例如 RLE,with direct operation on compressed data when using late-materialization plans.
- 作者自己还提出了一个 invisible join 的优化,能够提升延迟物化中的 join 性能。
论文通过在 CStore 中移除不同的优化手段,来度量它们的作用。如果压缩可行的话,则压缩能够提供数量级的提升。延迟物化能提升三倍性能。block iteration 以及 invisible join 提升 1.5 倍性能。
STAR SCHEMA BENCHMARK
这个 benchmark 是从 tpch 上派生出来的。不同于 tpch,它使用了纯粹的教科书级别的星形模型。它的查询比 tpch 要少。选择它主要是因为它比 tpch 更容易实现,所以就不需要修改 CStore 就能跑。
Schema:这个 benchmark 只包含一张事实表,也就是 lineorder 表,它合并了 tpch 中的 lineitem 和 orders 表。
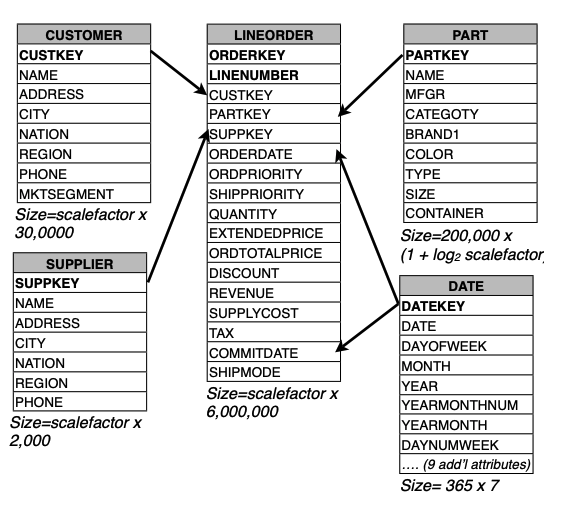
Queries:包含了 13 个 query,可以被分为 4 类,或者四个 flight:
- Flight 1 包含 3 个 queries。这些 query 的约束条件是 1 dimension attribute,以及 discount 和 quantity 列。目的是在不同折扣下计算 gain in revenue(EXTENDEDPRICE * DISCOUNT)。
- Flight 2 包含 3 个 query。约束条件是 2 dimension attributes。计算在特定 region 特定 produce class 的 revenue,并且按照 product class 和 year 去 group。
- Flight 3 包含 4 个 query。约束条件是 3 dimention attributes。计算特定区域的特定时间内的 revenue,按照 customernation、supplier nation 和 year 做 group。
- Flight 4 包含 3 个 query。Queries restrict on three dimension columns, and compute profit (REVENUE - SUPPLYCOST) grouped by year, nation, and category for query 1; and for queries 2 and 3, region and category. The LINEORDER selectivities for the three queries are 1.6×10−2 , 4.5×10−3 , and 9.1 × 10−5 , respectively
ROW-ORIENTED EXECUTION
Vertical Partitioning
在实现时,需要一个措施让属于相同的 row 的 field 能够彼此连接起来。在列存中这是隐式实现的,因为所有的列中的 field 都是按照相同的顺序来存储的。在行存中,一个简单的办法是对每个表中添加一个 position 列。这样每个 column都对应一个 physical 表,第 i 个表有两个 column,第一个是逻辑表中 column i 的值,第二个是 position 列中对应的值。Queries are then rewritten to perform joins on the position attribute when fetching multiple columns from the same relation. In our implementation, by default, System X chose to use hash joins for this purpose, which proved to be expensive. For that reason, we experimented with adding clustered indices on the position column of every table, and forced System X to use index joins, but this did not improve performance – 因为索引引起的额外的 io 导致了它比 hash join 还要慢。
Index-only plans
Vertical Partitioning 有两个问题。第一个是每个 column 都需要存一个 position 列,浪费空间和磁盘带宽。第二个是大多数行存会为每个 tuple 存一个相对比较大的 header,从而进一步浪费空间。而列存几乎总是将 header 存在各自的 column 中,从而避免类似的开销。【Q】这个 header 是指的为 MVCC 服务的隐藏列么?
因此,现在这个设计中,base relation 会被存在一个标准的行存中,但是一个额外的、unclustered 的 B+ 树索引会被加载每个 table 的每个 column 上。
Index-only plan 需要数据库的额外的支持。首先对每个表,建立满足 predicate (record-id, value) 对的 list,然后如果在同一个表上有多个 predicate,则需要在内存中 merge 这些 rids-list。当这些 fields 没有 predicate,那么就可以返回这一列中所有的 (record-id, value) 对。可以看到,这样的 plan 并不需要访问磁盘上的真实 tuple。虽然这些 index 能够显式存放 rid,但是它们不会存储一份重复的 value 了。所以,它有 a lower per-tuple overhead than the vertical-partitioning approach,因为 tuple header 并没被存在 index 中。
容易发现,这个问题是如果一个 column 上没有 predicate,就需要扫描一遍 index 从而去提取出需要的 value。相比于 vertical partition 的扫 heap file 会更慢一点。【Q】我理解就是这时候要回表,就比较慢。
一个优化是建立 composite keys 的索引。例如 SELECT AVG(salary) FROM emp WHERE age > 40 这个 query,如果建立了一个 (age, salary) 上的 composite index,就可以从这个索引中快速回答这个 query。如果我们为 age 和 salary 分别建立了索引,那么 index-only-plan 就需要首先根据 age 的索引找到所有的 record-ids,然后再去和整个 (record-id, salary) 列表去 merge,而这个就需要加载整个 salary 索引,所以就很慢了。
We use this optimization in our implementation by storing the primary key of each dimension table as a secondary sort attribute on the indices over the attributes of that dimension table. 这样,就可以有效访问 the primary key values of the dimension that need to be joined with the fact table.
Materialized Views
对于每个 query flight,狗仔一个 optimal set of materialized view,其中只包含所有需要的 column。我们没有 pre-join columns needed to answer queries in these views。Our objective with this strategy is to allow System X to access just the data it needs from disk, avoiding the overheads of explicitly storing record-id or positions, and storing tuple headers just once per tuple. 因此,我们期望它比其他两个方式表现更好,尽管它要求 query 的 workload 需要被提前知道。
COLUMN-ORIENTED EXECUTION
压缩
压缩实际上减少了磁盘使用,但是磁盘是越来越便宜的。但是,它还能提高性能。原因是如果数据变小了,那么通过 IO 从磁盘上读取这些数据的时间也就变少了。因此,在更高的压缩率和更快的解压速度之间是一个权衡。
特别地,如果能够在压缩的数据上直接执行计算,就可以避免解压。比如,RLE 这种将重复的 value 替换为 count 和 value 的做法。
Prior work [4] concludes that the biggest difference between compression in a row-store and compression in a column-store are the cases where a column is sorted (or secondarily sorted) and there are consecutive repeats of the same value in a column. In a columnstore, it is extremely easy to summarize these value repeats and operate directly on this summary. In a row-store, the surrounding data from other attributes significantly complicates this process. Thus, in general, compression will have a larger impact on query performance if a high percentage of the columns accessed by that query have some level of order.
延迟物化
优势:
- select 和 aggregation operator 可以不去构造某些元组。如果 executor 能在构造一个 tuple 时等待足够长的时间,就可以完全避免去构造。
- 如果数据被压缩,就需要在和其他 column 组合之前被解压。这样就失去了直接操作压缩数据的优势。
- Cache 利用率提高了。显然,我们可以不用加载一堆东西,从而污染 Cache。
- 后面的 Block iteration 优化对于定长的 attribute 的优化性能更强。row store 中,只要有一个 attribute 是变长的,那么整个 tuple 就是变长的,但是在 column store 中,列是单独存放的。
Block Iteration
为了处理一系列的 tuple,行存首先要遍历每个 tuple,然后提取需要的 attribute。这个提取通常需要几次函数调用。
在列存中,同一个 column 的 block 会被发送给一个 operator,所以就是一次函数调用。另外,也不需要提取 attribute 了。如果 column 是定长的,就可以以 array 的形式去遍历它。array 的形式还能实现并行处理,比如 loop-pipelining 技术。
Invisible Join
星型 schema 的 query 通常有如下的结构:通过一个或者多个 dimension table 上的 selection predicate 作为 fact table 上的约束条件。然后基于这个受约束的事实表上做一些聚合,通常是和其他的 dimention table 上的一些 attribute 去 group by。
因此,对于每个 selection predicate 以及每个 aggregate group 都需要执行一次 fact table 和 dimension table 的 join。
下面的 query 就是一个典型。传统的 plan 是 pipeline joins in order of predicate selectively。例如,如果 c.region = 'ASIA' 是最 selective 的 predicate,那么根据 custkey 去 join lineorder 和 customer 两个表就会被首先执行,这样就会过滤 lineorder 表,从而只有在 ASIA 的客户留下来。在这个 join 完成后,customer 的 nation 就会被加入到这个 join 后的 customer-order 中间表中。These results are pipelined into a join with the supplier table where the s.region = 'ASIA' predicate is applied and s.nation extracted, followed by a join with the data table and the year predicate applied. The results of these joins are then grouped and aggregated and the results sorted according to the ORDER BY clause
1 | SELECT c.nation, s.nation, d.year, |
另一种做法是延迟物化的方法。In this case, a predicate is applied on the c.region column (c.region = 'ASIA'), and the customer key of the customer table is extracted at the positions that matched this predicate. These keys are then joined with the customer key column from the fact table. join 的结果是两个 position 的集合,一个是给 fact table 的,一个是给 dimension table 的。它们表示了这两个表中各有那些 tuple 会被传给 join predicate,然后被 join。
一般来说,这两个 posision 集合中,最多只有一个是 sorted order,一般会是 outer table,也就是 fact table。Values from the c.nation column at this (out-of-order) set of positions are then extracted, along with values (using the ordered set of positions) from the other fact table columns (supplier key, order date, and revenue). Similar joins are then performed with the supplier and date tables.
上面两种方案都有缺点。第一种情况,每次 join 都需要构造一堆 tuple。第二种情况,从 dimension table group-by column 中的值是乱序被提取出来的。
To BLOB or Not To BLOB: Large Object Storage in a Database or a Filesystem?
这个论文我比较感兴趣,因为不少朋友在选型的时候面临这个问题:BLOB 应该被存在 fs 里面还是 db 里面呢?
需要注意到,这是一篇比较早的论文,正如文章指出的,随着 SSD 的普及,WAL 和 buffer pool 带来的优势减少了,因为 random write 的性能提高了。
Abstract
小于 256KB 的 blob,db 处理起来比较有效率,fs 对 1MB 以上的 blob 有效率。文章认为,最重要的影响因素是 storage age,也就是 deleted objects 对 live objects 的比值。当 storage age 增加时,fragmentation 就会增加。fs 研究能更好处理 fragmentation。研究中还说,只要平均大小是固定的,其分布如何并不显著影响性能。We also found that, in addition to low percentage free space, a low ratio of free space to average object size leads to fragmentation and performance degradation。
Background
fragmentation
NTFS文件系统使用基于“band”的分配策略来管理元数据,但对于文件内容则不是。【Q】这里的 band 是不是别的里面的 stripe?
NTFS 通过基于运行的查找缓存来为文件流数据分配空间。这些连续的空闲簇会根据大小和卷偏移量以降序排列。NTFS 尝试从外带开始满足新的空间分配请求。如果失败,它会使用空闲空间缓存中的大范围空间。如果这些尝试都失败了,文件就会被分割。此外,当文件被删除时,分配的空间不能立即被重用;必须先提交NTFS事务日志条目,之后释放的空间才能被重新分配。总体行为是文件流数据倾向于在文件内连续分配。
对于修改一个 existing object,fs 和 db 的处理方式不同。fs 会优化 append、truncate 这个文件。inplace file update 是有效率的,但是如果要在中间插入或者删除,那么就需要重写整个文件。但是对于某些 db 而言,在一个 object 里面增删性能会比较高,如果它们和 database page 是 align 的。如果 db 使用 B 树,那么就允许插入或者删除任意大小的数据,并且它们可以在任意位置。
应用也可以自己做 fragmentation,比如视频流是 chunked 的。
Safe writes
大部分文件系统都能够保护内部的元数据结构,比如目录或者文件名。比如当出现系统宕机或者电源故障的时候,文件系统的数据不至于破坏。但是对于文件的内容就没有类似的保证。特别地,文件系统和下层的操作系统会将写入乱序,从而提升性能。只有一些请求能够在一个 dirty shutdown 之后被完成。
不少桌面应用程序会选择使用一个叫 safe write 的技术,去保证当从一个 dirty shutdown 重启后,文件的内容要么是旧的,要么是新的,不会在某个中间不一致的状态。这种做法需要完全拷贝一份文件到磁盘中,哪怕大部分的内容没有发生变更。
safe write 的实现方法具体来说就是会创建一个临时的文件,然后写入新数据,然后 flush to disk,最后将文件重命名为原来的文件名,这样就可以同时删除掉原文件。这是因为 UNIX 系统中的 rename 是能保证原子性的。
相比之下,数据库提供了事务机制。应用可以安全的以任何方便的方式去更新数据。根据数据库的实现,相比像文件系统一样重新写入整个文件,只重写一部分更有效率。
下面是对 WAL 这个策略的介绍,不翻译了。
The database guarantees transactional semantics by logging both metadata and data changes throughout a transaction. Once the appropriate log records have been flushed to disk, the associated changes to the database are guaranteed to complete. The log is written sequentially, and subsequent database updates can be reordered to minimize seeks. Log entries for each change must be written; but the actual database writes can be coalesced – only the last write to each page need actually occur.
这样的坏处是要写两次数据。顺序写 WAL 类似于顺序写文件。在日志中写入的大的对象,可能导致日志需要被更频繁地截断,或者构建 checkpoint,这样 reorder 和 combine 这些 page 修改的机会少了很多。
Data centric web services
为了在 fs 和 db 之间能够“公平”对比,所以使用了 SQL Server 的 bulk-logging 模式。这个模式下,提供了事务的持久性。但是类似于 fs,它并不保证 large object 对象在一次 dirty shutdown 之后还是 consistent 的。
这里的 db 和 fs 实际上对 metadata 都是提供事务性的更新。会写一次 large object,并且只会写一次。不保证 large object data 是 consistent 的。
通过复制的方式去修复 corrupt 的数据。
Prior Work
Data layout mechanisms
介绍了一些不同的解决 fragmentation 的方案。
FFS:fragmentation aboiding allocation 算法对于磁盘占用在 90% 以内的是可以的。UNIX 需要保留一定的空间去做 disaster recovery,以及防止 excess fragmentation。
NTFS:当磁盘占用超过 75%,就会有一个 defragmentation 机制在跑了。后面会介绍他的一些缺点。
LFS:一个 log based fs。针对写入性能进行优化,将数据按照写入请求的 chronological order 组织写入到磁盘上。这使得写入时是顺序的,但是会产生严重的 fragmentation,如果文件被随机地进行更新。
WAFL:可以在传统以及写入优化之间进行切换。WAFL also leverages NVRAM caching for efficiency and provides access to snapshots of older versions of the filesystem contents. Rather than a direct copy-on-write of the data, WAFL metadata remaps the file blocks. A defragmentation utility is supported, but is said not to be needed until disk occupancy exceeds 90+%.
GFS(应该不是 Google FS):使用称为 chunck 的 64MB 的块,从而部分解决了 layout 的问题。提供了一个安全的 record append 操作,它允许多个 client 同时往一个文件 append 数据。这减少了产生 fragmentation 的可能。
下面是说,GFS 的 record 不会跨越 chunk。如果一个 record 在当前 chunk 放不下了,剩余空间就会被填上 0,然后这个 record 会在一个新的 chunk 的头部开始写入。这会产生很多的 internal fragmentation。
GFS records may not span chunks, which can result in internal fragmentation. If the application attempts to append a record that will not fit into the end of the current chunk, that chunk is zero padded, and the new record is allocated at the beginning of a new chunk. Records are constrained to be less than ¼ the chunk size to prevent excessive internal fragmentation. However, GFS does not explicitly attempt to address fragmentation introduced by the underlying file system, or to reduce internal fragmentation after records are allocated.
Comparing Files and BLOBs
测试环境
7200 转的机械硬盘,SATA 口。比较老旧了。
File based storage
For the filesystem based storage tests, we stored metadata such as object names and replica locations in SQL server tables. Each application object was stored in its own file. The files were placed in a single directory on an otherwise empty NTFS volume. SQL was given a dedicated log and data drive, and the NTFS volume was accessed via an SMB share.
这里还是用数据库的原因是避免实现复杂的 recovery 机制。
Database Storage
We also used out-of-row storage for the application data so that the blobs did not decluster the metadata. Although the blob data and table information are stored in the same file group, out-of-row storage places blob data on pages that are distinct from the pages that store the other table fields. This allows the table data to be kept in cache even if the blob data does not fit in main memory.
Storage age
提出这个 storage age 指标,也就是曾经写入的 bytes 比上现在还在用的 bytes。这个定义的假设是 free space 是相对来说固定的。
Results
out-of-the-box 场景下的吞吐量
也就是一开始 bulk load 之后的 read throughput。
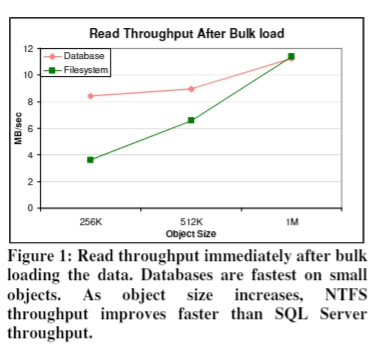
写入的 throughput,SQL Server 是优于 NTFS 的。对于 512 KB 的对象,数据库是 17.8 MB/s,NTFS 是 10.1 MB/s。
跑了一段时间的情况
这个时候要注意 fragmentation 对性能的影响。
首先,它说 SQL Server 没有发现和缓解 fragmentation 的方案。文章上说,隔段时间,把数据从老表复制出来到新表,然后再把老表 drop 掉可以实现 fragmentation。
To measure fragmentation, we tagged each of our objects with a unique identifier and a sequence number at 1KB intervals. We also implemented a utility that looks for the locations of these markers on a raw device in a way that was robust to page headers, and other artifacts of the storage system.
下图中的 overwrites 也就是 storage age。bulk load 对应的 storage age 就是 0。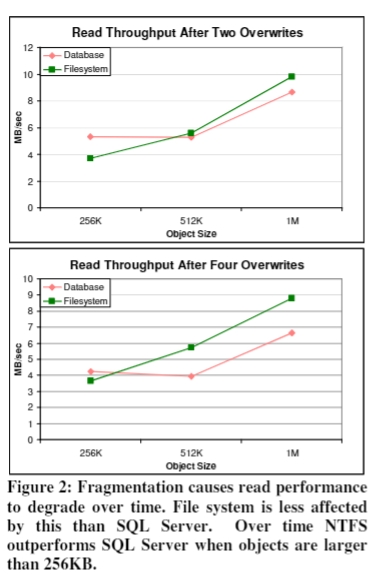
下图展示了,对于非常大的,比如 10MB 的对象,SQL Server 的性能很差,它的 fragments/object 基本上是线性的。NTFS 要好很多。The best-effort attempt to allocate contiguous space actually defragments such volumes. That experiment also suggests that NTFS is indeed approaching an asymptote in Figure 3.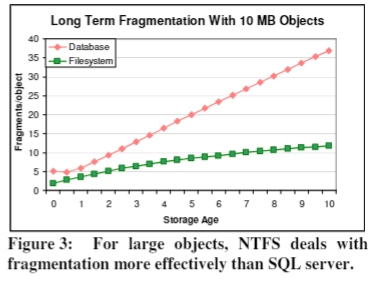
The degradation in write performance is shown in Figure 4. In both systems, the write throughput during bulk load is much better than read throughput immediately afterward. This is not surprising, as the storage systems can simply append each new file to the end of allocated storage, avoiding seeks during bulk load. On the other hand, the read requests are randomized, and must incur the overhead of at least one seek. 在 bulk load 之后,SQL Server 的写入性能急剧下降,NTFS 的写入性能要比读取性能稍微好点。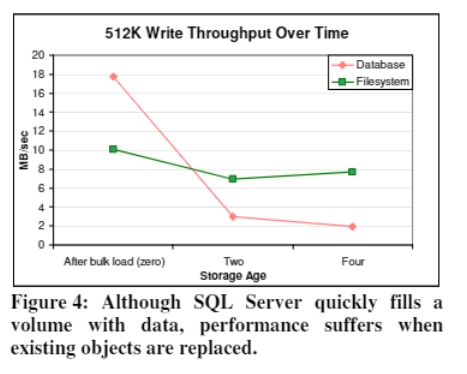
注意,不能直接比较 Figure 1 和 2 里面的写性能和读性能。因为读性能是在 fragmentation 之后度量的,写性能则是在 fragmention 这个过程中度量的平均值。
下面这个应该写错了。
To be clear, the “storage age four”(应该是 two 吧) write performance is the average write throughput between the read measurements labeled “bulk load” and “storage age two.” Similarly, the reported write performance for storage age four reflects average write performance between storage ages two and four.
Fragmentation effects of object size, volume capacity, and write request size
Cloud Programming Simplified: A Berkeley View on Serverless Computing
https://arxiv.org/pdf/1902.03383
Emergence of Serverless Computing
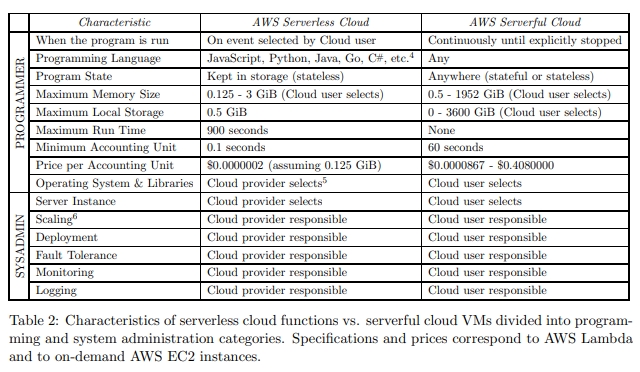
相比 serverful,serverless 的改变是
- 存算分离。存储和计算被分开提供和计费。存储一般是单独的服务,计算一般是无状态的。
- 代码执行不需要手动管理资源分配。用户提供代码,cloud 自动提供资源。
- 按使用量计费,而不是按照使用资源的规格计费。
Contextualizing Serverless Computing
例如 CGI 这样的机制,已经有了 stateless programming model,在此之上支持了 multi-tenancy、elastic response to variable demand 和 standardized function invocation API。CGI 甚至允许直接部署源码比如 PHP 来运行。
作者认为,现在的 serverless 相比 CGI 这样的古早方案,有三个特点:更好的自动扩缩容、强隔离、platform flexibility、service ecosystem support。
扩缩容:AWS Lambda 能够缩容到零实例实现零费用。它的计费是 100ms 级别的,而不是之前的小时级别。
隔离:VM 是实现高性能安全隔离的方式。AWS Lambda 解决了 VM 启动速度比较慢,支持不了快速弹性扩缩容的问题。它维护了两个 pool,warm pool 中包含的 VM 实例只是被分配给了某个 tenant,而 active pool 中的实例已经实际运行过了,并且一直保持着,以便维护后续的服务请求。还有除了 VM 之外的隔离方案,比如容器、unikernel、library OS 和语言虚拟机。比如一些使用了浏览器的 JavaScript 沙箱技术。
认为 k8s 并不是 serverless,而是简化了 serverful computing 的技术。k8s 能提供一个短生命周期的计算环境,类似于 serverless computing,但是限制更少,例如在硬件资源、执行时间和网络通信。只需要少量改动,就可以通过 k8s 让专门为 op 涉及的程序运行在云上。相比之下,Serverless 将运维的责任完全推给了服务提供商,然后要实现 fine-grained multi-tenant multiplexing。GKE 和 EKS 应该是介于这两个中间的一个东西,它帮用户运维 k8s,但是容器还是用户来自定义的。K8s 服务和 serverless 服务的区别之一是 billing model。前者为 reserved resource 计费,后者为 per function execution duration 计费。
K8s 还会是一个 hybrid application 的好选择。也就是一个程序一部分是 op 部署的也就是在本地硬件上,另一部分是 cloud 部署的。
Attractiveness of Serverless Computing
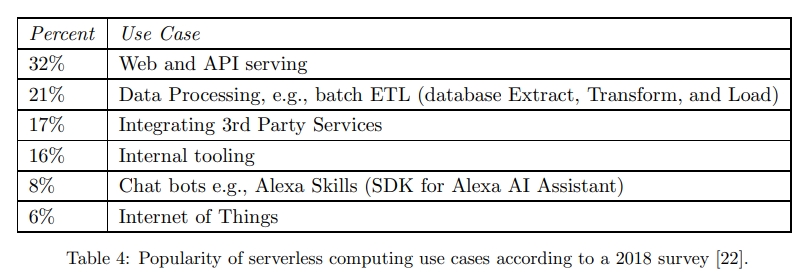
Limitations of Today’s Serverless Computing Platforms
本节选择了五个传统的 serverful 的云计算应用,然后尝试只使用 cloud functions 来实现它们的 serverless 版本。
- ExCamera 实时视频编码。把编码过程中比较慢的并行化,比较快的继续串行化。
- MapReduce 目前一些 Map-only 的任务被移动到 serverless 上。
- Numpywren 线代。一般这样的任务是部署在超算或者高性能计算集群上的。这样的集群需要高速低延迟的网络。serverless 从历史上来讲,不太合适。但是一方面,数据科学家维护大集群很麻烦,另一方面,线代的并发又是波动很厉害的。所以这是 serverless 的机会。
- Cirrus:机器学习训练。传统上使用 VM 集群处理 ML 工作流上面的不同任务,比如预处理、模型训练、参数调节。不同的这些任务所需要的资源是完全不同的。serverless 可以给每个阶段提供合适的容量。
- Serverless SQLite:数据库。首先,serverless 计算没有内置的持久化存储,需要访问远程存储,带来网络开销。其次,client 需要通过网络地址连接数据库,而 serverless 的 cloud function 并没有暴露出网络。最后,很多高性能的数据库是 share-everything 的,比如共享磁盘,共享网络等,但 serverless 基本肯定是不能共享内存的。即使是 share-nothing 数据库,它们也是需要通过网络来互相访问的。
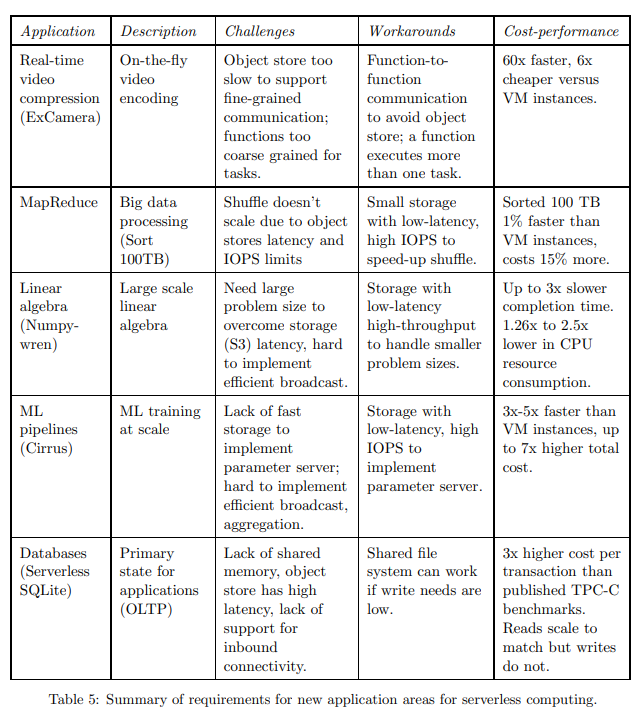
Inadequete storage for fine-grained operations
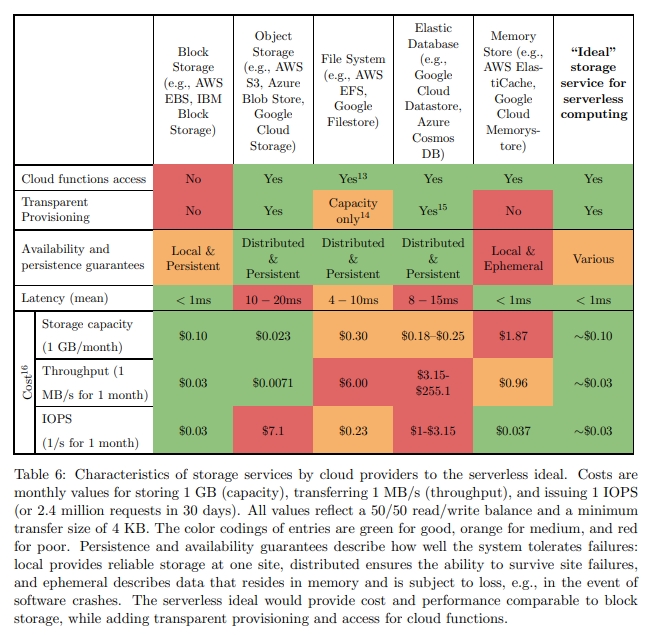
这一章节中列出了目前云服务商提供的一些外部存储服务。
诸如 AWS S3、Azure Blob Storage 和 Google Cloud Store 这样的 long-term OSS 的访问开销以及延迟会比较大。测试中,读写小对象有 10ms 左右的延迟。
诸如 DynamoDB、Azure Cosmos 这样的 KV 数据库提供了很高的 IOPS,但是很昂贵,并且 scale up 很耗时间。
有一些 in-memory 数据库,但是它们没有容灾,也不能 autoscale。
Lack of fine-grained coordination
为了支持有状态服务,serverless 需要支持两个 task 之间的通信协调。特别是一些需要通信来保证一致性的服务。
云服务商会有一些比如 SNS 或者 SQS 的 notification 服务,但是它们的延迟很高,并且代价很大。现在的选择是要么使用一个 VM-based system 来提供通知,要不就是自己实现一套通知机制。
Poor performance for standard communication patterns
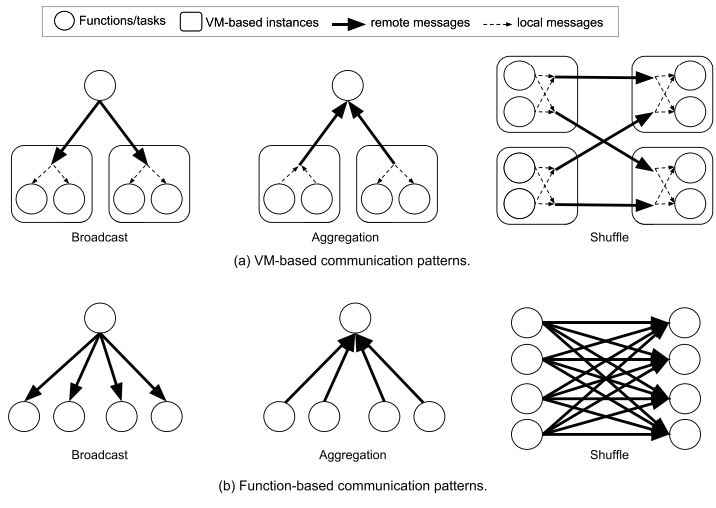
Broadcast、aggregation 和 shuffle 是分布式系统中的通用原语。下图中比较了三种原语在 VM 以及 cloud function 两个场景下的实现。可以发现,VM-based 场景下的 remote 消息是显著少的。因为很多消息可以是本地的,或者通过其他方式进行共享。
另外,即使发消息,也可以将消息进行打包,这样两个 VM node 之间实际上只要传递一个消息。
Predictable Performance
尽管 cloud function 的启动时间比 VM 短,但是启动新实例的代价,对于某些 app 来说会更高。三个影响 cold start 延迟的因素:
- 启动 cloud function 的时间
- 启动 function 的软件环境的时间,比如 python 库的加载
- 用户代码中的初始化。
后两者会拖累第一个。比如可能启动一个 cloud function 就不到一秒,但是加载所有的库要花十秒。
另外,使用的底层硬件对用户来说是透明的,有的时候,用户可能会被分配到更老的处理器上。这是云服务商在做调度的时候的权衡。
What Serverless Computing Should Become
Abstraction challenges
Resource requirements
目前可以定制的只是内存大小以及执行时间,但是对于 CPU、GPU 这些资源则不能。允许开发者进一步去指定,增加云服务提供商进行调度的难度。也需要开发者去进一步关注这些事情,这是违背 serverless 的精神的。
更好的做法是提高抽象程度,让云服务提供商去推断。云服务商可以从静态代码分析,profile 过去的 run,动态编译面向特定平台的代码这些方面去做。
要精确预计需要多少内存也是很有挑战性的工作。一些想法是整合语言运行时到 serverless 平台上,这样可以去访问这些语言的 GC 模块。
Data dependencies
很难知道各个 cloud function 在数据上的依赖关系。比如谁是谁的前序,谁依赖谁的结果这样。特别还有很多 cloud function 是 exchange 数据的,这让情况更复杂。
一种做法是供应商提供一个 API,让用户去提供一个计算图,这样就可以有更好的 placement decision,使得通信变少。
System challenges
High-performance, affordable, transparently provisioned storage
Serverless Ephemeral Storage 和 Serverless Durable Storage。
Serverless Ephemeral Storage 可以被部署在 in-memory 的分布式服务中,同时需要一个优化的网络。这样就是 microsecond 级别的延迟。还需要能够快速扩缩容。它能够透明地分配,以及释放内存。也就是当 app 挂掉或者正常退出时,它能够自动回收它使用的存储空间(当然是 in-memory)的。
诸如 RAMCloud 和 FaRM 的缺陷是,需要显式地估算要使用的 storage。他们也不提供租户之间的强资源隔离。Pocket 缺少自动扩缩容,需要预先分配空间。
可以通过 statistical multiplexing 来节省内存,也就是如果有人用不到这么多内存,就可以先挪过去给别人用了,就是超卖。即使对于同一个 app 也还是有好处的,比如说不同的服务,原来可能是部署在不同的 vm 上的,现在可能就是能运行在一个 vm 上了。当然,serverless 也还是存在 internal fragmentation 的。
Serverless Durable Storage 主要是通过一个 SSD 的分布式 store,以及一个 in-memory 的 cache 实现的。这个设计的难点是如何在有较高的 tail access distribution 的情况下达到比较低的 tail latency,考虑到内存 cache 的容量比 SSD 的容量实际上要小很多。
类似于 Ephemeral Storage 它也需要能够被透明而不是显式地预测内存,并且能够提供跨租户和 app 之间的隔离。不同于 Ephemeral Storage,Durable Storage 只允许显式回收存储,也就是 app 被 terminate 的时候,不应该自动回收 storage。
Coordination/signaling service
一般使用生产者-消费者模型来实现在函数之间分享状态。这就需要当数据被生产出来时,消费者能够尽早知道。同样对生产者也是如此。这样的信号系统,需要满足 microsecond 级别的延迟、可靠的投递、支持广播或者组播。当然,因为 cloud function 并不是有独立的地址的,所以我们难以实现教科书级别的共识,或者选举机制。
Minimize startup time
启动时间包含:
- 调度资源
- 下载环境,比如 OS、库
- 执行每个 app 自己的启动和初始化逻辑
第一部分在创建隔离环境,以及用户的 VPC 和 IAM 阶段可能有显著的延迟。哦,之前不是说这个很快的么?哦,所以最近有一些办法,比如使用 unikernel。它 preconfigure 系统到硬件上,相当于把监测硬件、分配 os 数据结构等变成静态的了。另一方面,它只包含 app 需要的驱动和系统库。
另一个解决第二部分的方式,是动态或者增量地加载 app 需要的库。
云提供商可以提供一个 signal 机制,让一个应用在自己能处理的时候,调用这个信号进行通知,然后接受负载。此外,云提供商还可以基于预测,提前启动。这种方案非常适合去处理那些和具体用户行为不相关的任务,比如启动 OS 或者加载库,这样就得到了一个可以被所有 tenant 共享的 warm pool 了。
Networking challenges
如前文介绍的,serverless 的 broadcast、agg、shuffle 操作的通信成本都比较大。解法:
- 增加 cloud function 的核数,这样就能够合并多个 task 的通信
- 允许开发者显式将一些 cloud function 部署到同一个 VM 上。
- 让 app 开发者提供一个计算图,让 cloud provider 可以去 colocate 这些 cloud function。这个计算图,可以参考 Abstraction Challenges 的论述。
前两者有点违背 serverless 精神,并且可能无法有效利用资源。
Security challenges
暂不关注安全,略
Computer architecture challenges
Hardware Heterogeneity, Pricing, and Ease of Management
现在硬件都要接近瓶颈了:
Alas, the x86 microprocessors that dominate the cloud are barely improving in performance. In 2017, single program performance improvement only 3% [69]. Assuming the trends continue, performance won’t double for 20 years. Similarly, DRAM capacity per chip is approaching its limits; 16 Gbit DRAMs are for sale today, but it appears infeasible to build a 32 Gbit DRAM chip. A silver lining of this slow rate of change is letting providers replace older computers as they wear out with little disruption to the current serverless marketplace.
几个方案:
- 像 JS 或者 Python 这样的语言写的 cloud function,hardware-software co-design could lead to language-specific custom processors that run one to three orders of magnitude faster. 我不知道具体指的是啥。
- DSA(Domain Specific Architectures)。比如 GPU 适用于图形,TPU 适用于机器学习。
因此,serverless 需要支持一些 hardware heterogeneity:
- 支持多种实例类型,硬件不一样,价格就不一样
- 可以自动选择 language-based 加速器,和 DSA。这可以通过选择不同的库,或者语言来隐式实现。例如对 CUDA 代码使用 GPU,对 Tensorflow 代码使用 TPU。
对于 x86 的 SIMD 来说,Serverless 计算也面临一些 heterogeneity。但是现在 serverless 用户在 AWS Lambda 上似乎还不能够声明自己想要什么样的 CPU,并且他们的价格也是相同的。
Fallacies and Pitfalls
Fallacies 指的是谬误。一个谬误是觉得 Serverless 更贵。原因是相同内存规格的 AWS cloud function 比 AWS t3.nano 要贵 7.5 倍。
错误点:
- 价格中包含了冗余,监控,日志等一个 t3.nano 节点享受不了的东西。
- 扩缩容灵活,如果不调用就不收费。
Pitfall 指的是陷阱。这里说的是 Serverless 计算可能有未预期的成本。
这个是比较合理的担忧。解法是基于桶的定价,或者能够根据历史预测成本。
另一个 Fallacies 是采用诸如 Python 的高级语言,就很容易在不同的 Serverless 供应商之间移植 app。
错误点是不同的 Serverless 供应商之间的 API 不同。没有像 POSIX 一样的标准。
Pitfall: Serverless 计算的供应商锁定可能比 Serverful 计算更强。
另一个 Fallacies 是云函数无法处理需要可预测性能的 low-lentency 应用程序。
Serverful 能,是因为它一直是在线的。所以 Serverless 也可以做 pre-warm。
Pitfall:少有所谓的 elastic 服务能满足 serverless 计算的灵活性。
一大段话,懒得翻译了,大概就是说现在叫 elastic 的实际上还不如 serverless 呢。
The word “elastic” is a popular term today, but it is being applied to services that do not scale nearly as well as the best serverless computing services. We are interested in services which can change their capacity rapidly, with minimal user intervention, and can potentially “scale to zero” when not in use. For example, despite its name, AWS ElastiCache only allows you to instantiate an integral number of Redis instances. Other “elastic” services require explicit capacity provisioning, with some taking many minutes to respond to changes in demand, or scaling over only a limited range. Users lose many of the benefits of serverless computing when they build applications that combine highly-elastic cloud functions with databases, search indexes, or serverful application tiers that have only limited elasticity. Without a quantitative and broadly accepted technical definition or metric—something that could aid in comparing or composing systems—“elastic” will remain an ambiguous descriptor

