这篇文章中,包含 DuckDB、BitCask、Hologres、Cockroach。
DuckDB
https://mytherin.github.io/papers/2019-duckdbdemo.pdf
Intro
SQLLite 的使用,显示了对 embedding 的数据库的需求。DuckDB 是一个 embedding 的 OLAP。
之前做了个 MonetDBLite,但是发现还是要专门设计一个。原因:
- 需要高性能处理 OLAP workload,但是对 OLTP 的影响有限
- 比如做 dashboard 的时候,并发的数据修改很常见。比如很多线程在用 OLTP 去修改数据,另外一些线程用 OLAP 去生成可视化。
- 稳定性
- 如果内置的 db 挂掉了,比如 OOM 了,它不会把宿主程序给崩掉。而是让查询 abort。
- 数据库和应用程序在一个进程里面,应该利用这一点,提高数据分享和传递的效率
- 可移植性
- 比如对 openssl 这样的库的依赖实际上是很麻烦的
- 一些系统调用比如 exit 应当被禁止
DESIGN AND IMPLEMENTATION
Parser 从 postgql 上弄下来的。
Logical planner 由 binder 和 plan generator 组成。binder 将所有的 expression 关联到具体的 schema 对象,比如 table 或者 view 上。logical plan generator 将 parse tree 转成一个基本的 logical query operator,比如 scan、filter。project 等。在 planning 阶段之后,我们就有一个 type-resolved 的 logical query plan 了。
DuckDB 会统计已存储数据,这些统计信息回在 planning 过程中被传播,给 optimizer。
优化器进行 join order 优化。是通过 dynamic programming with a greedy fallback for complex join graph 来做的。It performs flattening of arbitrary subqueries。
DuckDB’s optimizer performs join order optimization using dynamic programming [7] with a greedy fallback for complex join graphs [11]. It performs flattening of arbitrary subqueries as described in Neumann et al. [9]. In addition, there are a set of rewrite rules that simplify the expression tree, by performing e.g. common subexpression elimination and constant folding.
Cardinality estimation is done using a combination of samples and HyperLogLog. The result of this process is the optimized logical plan for the query. The physical planner transforms the logical plan into the physical plan, selecting suitable implementations where applicable. For example, a scan may decide to use an existing index instead of scanning the base tables based on selectivity estimates, or switch between a hash join or merge join depending on the join predicates.
DuckDB uses a vectorized interpreted execution engine [1]. This approach was chosen over Just-in-Time compilation (JIT) of SQL queries [8] for portability reasons. JIT engines depend on massive compiler libraries (e.g. LLVM) with additional transitive dependencies.
DuckDB uses vectors of a fixed maximum amount of values (1024 per default).
- Fixedlength types such as integers are stored as native arrays.
- Variable-length values such as strings are represented as a native array of pointers into a separate string heap.
- NULL values are represented using a separate bit vector, which is only present if NULL values appear in the vector.
- This allows fast intersection of NULL vectors for binary vector operations and avoids redundant computation.
To avoid excessive shifting of data within the vectors when e.g. the data is filtered, the vectors may have a selection vector, which is a list of offsets into the vector stating which indices of the vector are relevant [1]. DuckDB contains an extensive library of vector operations that support the relational operators, this library expands code for all supported data types using C++ code templates.
The execution engine executes the query in a so-called “Vector Volcano” model. Query execution commences by pulling the first “chunk” of data from the root node of the physical plan. A chunk is a horizontal subset of a result set, query intermediate or base table. This node will recursively pull chunks from child nodes, eventually arriving at a scan operator which produces chunks by reading from the persistent tables. This continues until the chunk arriving at the root is empty, at which point the query is completed.
持久化的存储层中,DuckDB 使用 read-optimized DataBlocks storage layout。逻辑表被水平划分为 chunks of columns。后者被压缩到 physical blocks 中。Block 中有每个列的 min-max 索引,所以可以快速检查它们是否对查询相关。
Bitcask
https://arpitbhayani.me/blogs/bitcask/
Datafile 是 append-only 的 log file。它里面存放了 KV pair,以及一些 meta 信息。一个 Bitcask 实例有多个 datafile,其中一个是 active 并且接受写入的,另外的只读。
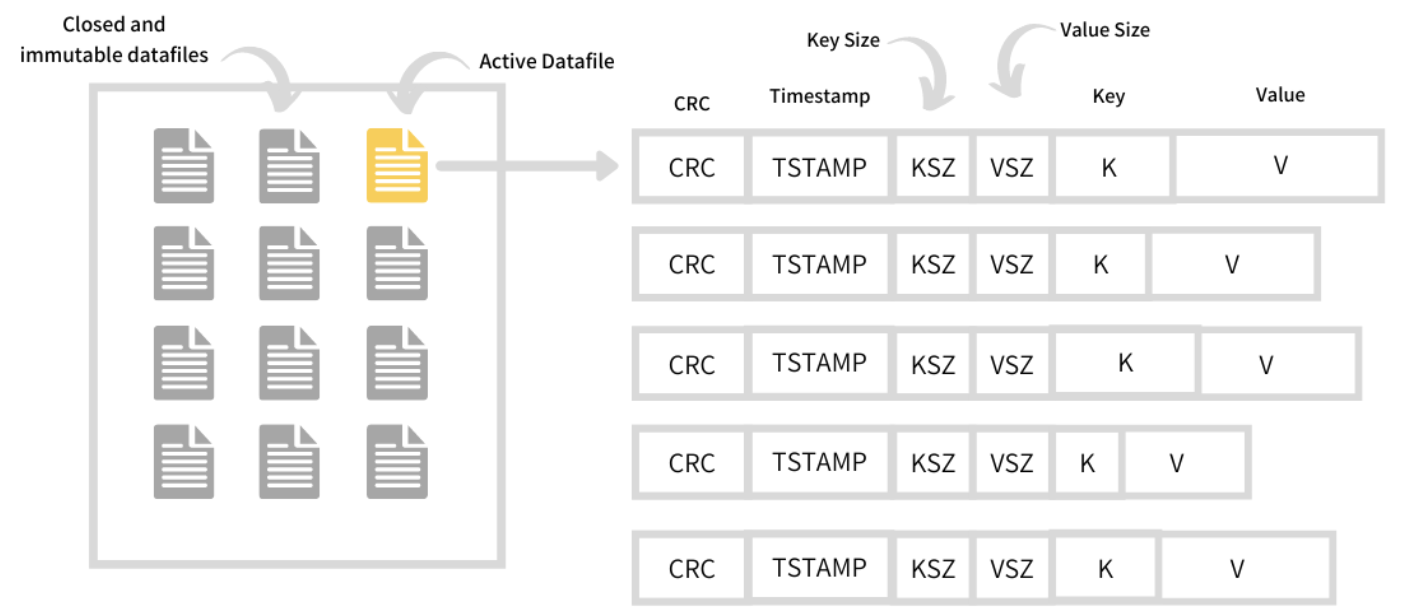
KeyDir 是一个内存中的 hash table。它存放 bitcask 中的所有的 key,以及它们在 data file 中的 offset。这个 offset 指向了 log entry,也就是 value 在的地方。这样做方便了点查。
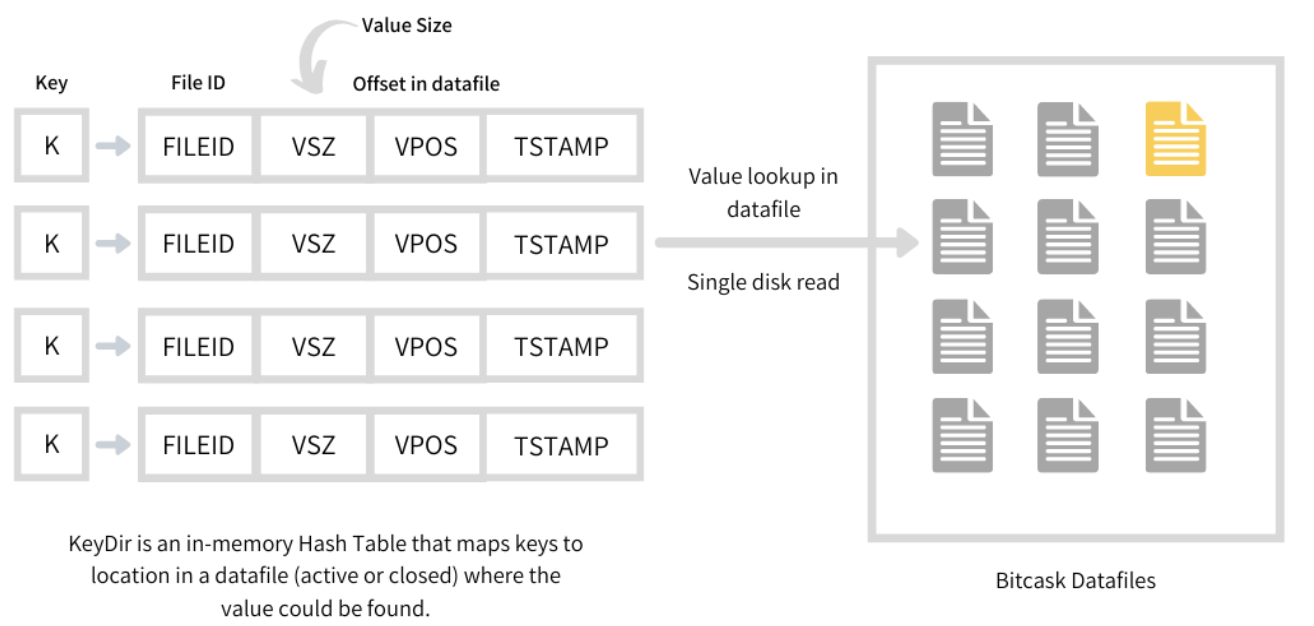
Merge and Compaction
The merge process iterates over all the immutable files in the Bitcask and produces a set of datafiles having only live and latest versions of each present key. This way the unused and non-existent keys are ignored from the newer datafiles saving a bunch of disk space. Since the record now exists in a different merged datafile and at a new offset, its entry in KeyDir needs an atomic updation.
Performant bootup
如果 Bitcask 从 crash 中重启恢复,就需要读取所有的 datafile,然后建立一个新的 KeyDir。Merging 和 Compaction 因为能 evict 陈旧的数据,所以能帮助减少要读取的数量。但是还有一个别的方式。
对于每个 datefile,创建一个 hint file。它持有 datafile 中从 value 之外的东西,也就是 key 和 meta。这个 hint file 其实很小,所以通过读取这个文件就可以快速创建 KeyDir 了。
Weakness
KeyDir 在内存中存放着所有 key。对系统的内存要求很高。
但是可以通过水平扩容的办法来解决。
Hologres
Alibaba Hologres: A Cloud-Native Service for Hybrid Serving/Analytical Processing
https://www.vldb.org/pvldb/vol13/p3272-jiang.pdf
一个 TGS 包含一个 WAL,以及一系列 Tablet。一个 Tablet 如同一个 LSM 树。各自拥有一个 Memtable,Memtable 被 flush 成为 shard file。
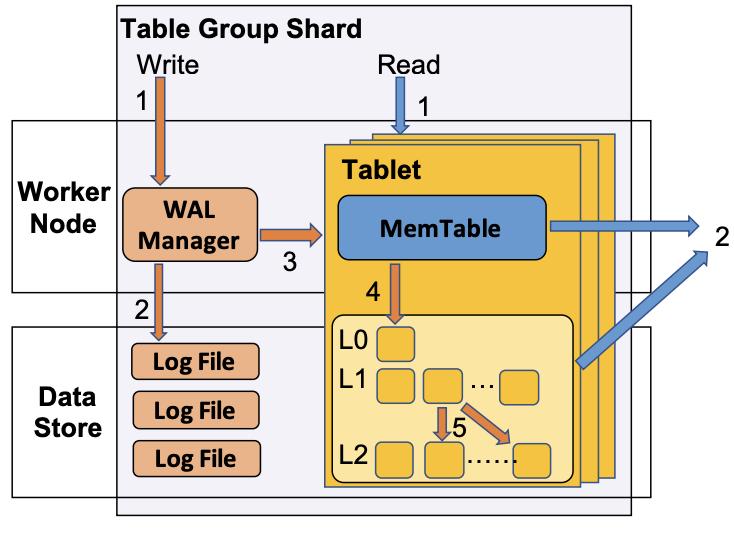
Single-shard Write. 在上图中,收到一个 single-shard ingestion 之后,WAL 首先分配一个 LSN。这个 LSN 是一个混合,包含了时间戳和一个自增的 seq。然后 WAL 会创建并持久化一个新的 entry。在持久化之后,write 就完成了。然后就是要写到 Memtable 里面,并且要对后续的用户可见。
Distributed Batch Write. 是个 2PC。FE 节点首先收到 batch write 请求,然后锁住所有访问到的 tablet。在每个 TGS 里面:
- 为 batch write 分配一个 LSN。
- flush 所有涉及到的 tablet 的 memtable。
- loads the data as in the process of single-shard ingestion and flushes them as shard files.
这一步可以通过使用多个 memtable,然后并行 flush 来优化。我理解这里就是直接 ingest 成 sst。一旦完成,每个 TGS 向 FE 投票,当 FE 收到所有 TGS 的投票后,它会通知 commit 或者 abort。如果决定 commit,每个 TGS 会持久化一个 log,表示 batch write 被 commit 了。否则 batch write 会被移除。在 2PC 完成后,会去掉 tablet 上面的锁。
每个 read 请求包含一个 timestamp,用来构造一个 LSN_read。它被用来 filter 掉所有应该对自己不可见的 record。比如所有 LSN 更大的 record。
一个 TGS 会对每个 table 维护一个 LSN_ref,保存 the LSN of the oldest version maintained for tablets in this table。LSN_ref 会被定期 update,用户可以配置这个时间,通过指定自己想要的 retaining period。在 memtable flush 和 file compaction 期间:
- 所有 LSN 小于等于 LSN_ref 的记录
- 所有比 LSN_ref 大的记录会被保留
目前实现中,一个 TGS 的 writer 和所有 reader 都在同一个 worker node 中。但是如果 worker node 压力大,可以 migrate 一些 TGS 出去。
后面可以做到 replica read。两种方式:
- fully-sync 的 replica,可以读到 up-to-date的数据
- partically-sync 的 replica,只能读到已经被 flush 到文件系统中的数据,也就是说读不到 memtable。
根据 read version,不同的读可以被 dispatch 到不同的 replica 上。但是所有的 read-only replica 都不需要实际复制这些 shard file,因为它们被存放在专门的分布式文件存储中。
有两种类型的 tablet,row 和 column。
row tablet 用来优化点查性能。memtable 是用 Masstree 来维护的,shard files 是 block-wise structure。shard file 包含 data block 和 index block。连续的 records 组成一个 data block,在 index block 中记录每个 data block 的 starting key,格式记录为 <key, block_offset>。
为了支持多版本,在 row tablet 中的数据会多加 del_bit 和 LSN 两列。对于同一行,memtable 和 shard file 中可能有多个记录,但是 LSN 是不同的。
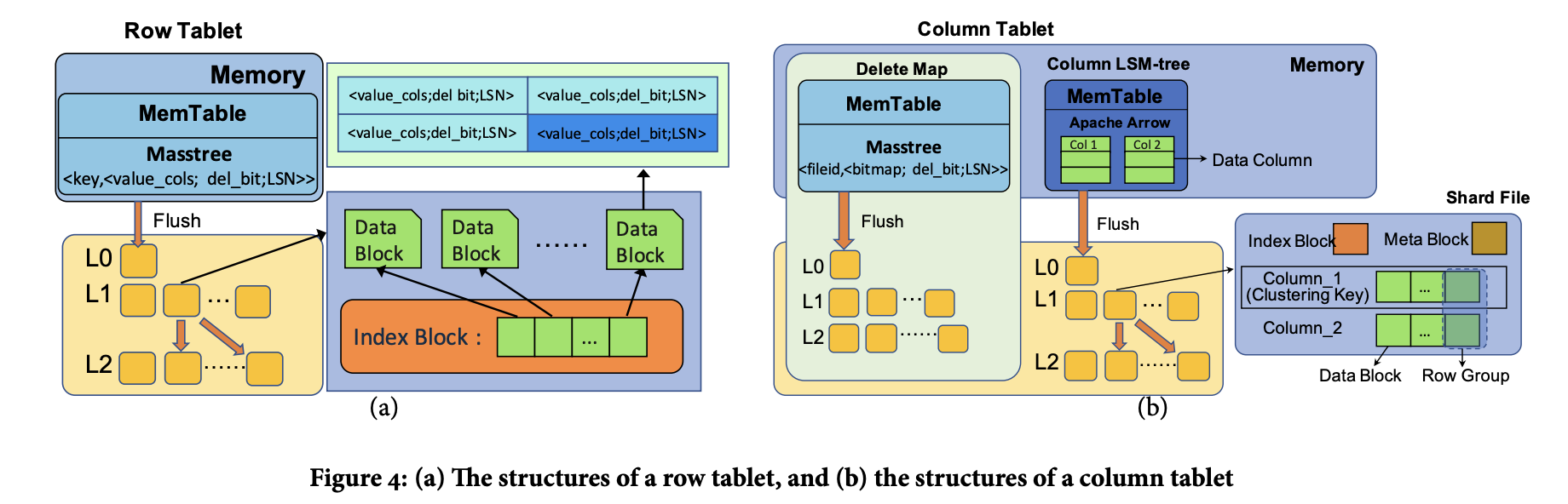
在 row tablet 里面的每一个 read 都包含一个 key,以及一个LSN_read。这个结果是通过搜索 memtable 和 shard file 完成的,两者可以并行做。所有 LSN 小于等于 LSN_read 的 key 都是candidate,然后会被按照 LSN 顺序进行 merge。如果看到 del_bit 是 1,或者找不到candidate record,就说明没找到。
写入包含了 key、value 和 LSN_write。删除也是一种写入,只是 del_bit 为 1。
Column tablet 被设计来辅助 column scan。它包含一个 column LSM 和一个 delete map。column LSM 树中的 value 实际上包含 value col 以及 LSN。memtable 按照 Apache Arrow 的方式来存储,records 根据 arriving order 在 memtable 中存储。row group 中的每一个 column 会被存为一个独立的 data block。同一个 column 的 data block 会被连续地存储在 shard file 中,从而优化顺序 scan。我们在 meta block 中维护每个 column 和整个 shard file 的 meta data,从而加速 large-scale data retrieving。在 meta block 中存有:
- 每个 column 在 data block 中的唯一
- 每个 shard file 的压缩算法、总行数、LSN 和 key 的 range。
在 index block 中存有 sorted first keys of row groups。
Thee delete map is a row tablet, where the key is the ID of a shard file (with the memory table treated as a special shard file) in the column LSM tree, and the value is a bitmap indicating which records are newly deleted at the corresponding LSN in the shard file. With the help of the delete map, column tablets can massively parallelize sequential scan as explained below.
用 LSN_read 读,会从 memtable 和所有的 shard file 中读取。在扫描一个 shard file 前,会根据 LSN_read 进行判别:
- 如果 minimum LSN 比 LSN_read 大,那么这个 file 被 skip 掉
- 如果 minimum LSN 小于等于 LSN_read ,那么这整个 file 都会对这个 read 版本可见
- 否则,这个 file 中只有一部分可见
读取:在第三种情况中,会扫描这个 file 的 LSN column,生成一个 LSN bitmap,用来决定哪些 row 是可见的。然后我们会通过 shard_file 的 ID 读取 delete map,获取哪些 row 是被删除了的。获得的 bitmap 回合 LSN bitmap 取交集,最终得到去除了 delete 和 invisible row 的最终结果。注意,不同于 row tablet,在一个 column tablet 中,每个 shard file 可以被独立读取,而不需要 consolidate 不同 level 的 shard file,因为 delete map 可以根据 LSN_read 和 shard file 的 ID 去有效率地返回哪些 row 是被删除了的。
【Q】我理解这样的话,delete map 是不是本身也要支持版本?其实另一个做法是不独立维护 version 列(这里的 LSN)列了,而是在删除的时候,直接记录 pk->{deleted, LSN}
写入:删除操作中,会根据 key 找到我们要在哪个 shard file 中删除这个 row,以及对应的 row number。我们会在 LSN_write version 上,对这个 delete map 中进行一次插入,此时 key 是 file ID,value 是被删除了的 row number。update 操作就是先删除后插入。
Hierarchical Cache
三层 cache 来减少 IO 和计算的开销。分别是 local disk cache、block cache 和 row cache。每个 tablet 对应了分布式系统中存储的一系列 shard file。local disk cache 用来在 local disk 也就是 SSD 中 cache shard file,从而减少 file system 中昂贵的 IO 操作。在 SSD cache 上面,有个内存中的 block cache。为了兼容行存和列存的不同的 data access pattern,将 block cache 分为行存和列存。在 block cache 上面,我们有一个内存中的 row cache,去存储最近 row tablet 中的点查的结果。
QUERY PROCESSING & SCHEDULING
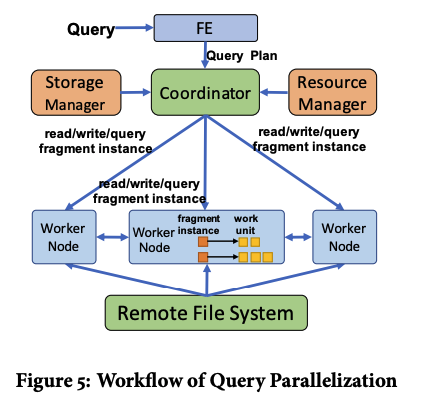
收到一个 query 后,FE 中的 optimizer 会生成一个 DAG 显示的 query plan。将这个DAG 按照 shuffle boundaries 分成多个 fragment。有三种 fragment:read、write、query。一个 read 或者 write fragment 包含一个访问 table 的 operator。一个 query fragment 只包含非 read 或者 write 的 operator。一个 fragment 会随后被并行化为多个 fragment instance,这是通过 data parallel 的方式,比如一个 read 或者 write fragment instance 会在一个 TGS 中处理。
FE node 将 query plan 发送给 coordinator。这个 coordinator 会随后将 fragment instance 发送给 worker nodes。read write fragment instance 总是会被发送到 host 对应 TGS 的 worker node。query fragment 可以被在任何 worker node 上执行。因此,会从 load balancing 的角度进行 dispatch。locality 和 workload information 会和 storage manager 以及 resource manager 分别进行同步。
在 worker node 中 fragment instance 会被 map 到多个 work units 也就是 WU 中。这是 Hologres 中的基本的query 执行单位。一个 WU 可以在运行期动态地 spawn 另一个 WU。具体规则是:
- 一个 read fragment instance 会被 map 到一个 read-sync WU 上。这个 WU 会 fetch 当前 tablet 的 version(从 metadata file 中获得的)以及一个 memtable 的只可读 snapshot,以及一个 shard file 的列表。然后 read-sync WU 会创建多个 read-apply WU,它们会并行读取 memtable,以及 shard file,并且会执行下游的任务。这个机制能够充分利用 high intra-operator parallelism,从而更好利用网络和 IO 的带宽。
- 一个 write fragment instance 会将所有的 non-write operator 去 map 到一个 query WU 中。后面会跟着一个 write-sync WN,它会将 log entry 持久化到 WAL 中。write-sync WU 会生成多个 write-apply WU,它们并行执行任务,其中每个 WU 会更新一个 tablet。
- 一个 query frament instance 会被映射到一个 query WU 上。
当并行处理多个不同用户发来的 query 的时候,WU 中的 context switch 成为 一个瓶颈。因此,Hologres 提供了一个用户态的线程,称为 execution context 即 EC。 EC 是 WU 的 resource abstraction。线程是可以 preemptively scheduled 的,但是 EC 是 cooperatively schedule 的。这样,就不涉及 system call 或者同步元语了。所以在 EC 之间的 switch 就是可以被忽略不计的了。Hologres 将 EC 作为基础的调度单位,计算资源按照 EC 来调度,一个 EC 会在被 assign 的线程上执行。
在 worker node 上,将 EC 分到多个 pool 中,从而保证隔离性以及 prioritization。EC pool 可以被分为三种类型:data-bound EC pool、query EC pool 和 background EC pool。
- data-bound EC pool 有两种类型,WAL EC和 tablet EC。在 TGS 中,有一个 WAL EC,和多个 tablet EC。每个 tablet RC 对应一个 tablet。WAL EC 执行 write-sync WU,tablet EC 执行 write-apply WU 和自己 tablet 上的 read-sync WU。WAL 或者 tablet EC 总是串行的处理所有的 WU,所以避免了同步措施。
- 在 query EC pool 中,每个 query WU 或者 read-apply WU 会被 map 到一个 query EC 上。
- 在 background EC pool 中,EC 会被用来 offload 昂贵的工作。比如 memtable flush 或者 shard file compaction 等。
下面是一个 EC 的内部结构。
首先包含两个 task queue。第一个是一个 lock free 的 internal queue,包含了所有这个 EC 提交的 store task。另一个是线程安全的 submit queue,包含了其他 EC 提交的 store task。当开始 schedule 的时候,在 submit queue 中的 task 会被移动到 internal queue 中,从而可以被 lock-free schedule。在 internal queue 中的 task 总是被 FIFO 地 schedule 的。
在一个 EC 的生命周期中,它会在三个状态中切换,即 runnable、blocking 和 suspended。suspended 状态表示 EC 被调度,因为 task queue 都是空的。一旦往里面提交任务,EC 就会变为 runnable 状态,从而可以被调度。如果 EC 中所有的任务都 block 了,比如 IO stall 了,EC 会被换出去,然后状态变为 blocking。一旦收到新的 任务,或者 block task 返回了,它又会变成 runnable 状态。EC 可以被外部 cancel,或者 join。Cancel 会导致未完成的 task fail 掉。EC 在 join 之后,就不能接受新的任务了,然后会在已有的任务完成后 suspend 自己。EC 是在系统线程池上被 cooperatively 调度,所以线程切换开销忽略不计。
Hologres 支持联邦查询,包括从 Hive 或者 HBase 获取数据。这些其他系统会被抽象为特殊的 WU,每个会被映射为一个 EC。处于系统安全的考虑,这些抽象会在一个沙盒中被运行。
Cockroach
https://dl.acm.org/doi/pdf/10.1145/3318464.3386134
Intro
这一部分主要讲了在很多国家要求数据被存放在自己的领土上,所以用户有需求去更精细的控制数据存放的位置。也就是它提到的 Geo-distributed partitioning and replica placement。
然后是他们提出的实物模型。它们只支持 serializable的隔离级别。它们认为 NTP 这样的 clock sync 机制已经是足够的。CRDB 也支持云部署。
SYSTEM OVERVIEW
CRDB 是一个 shared-nothing 模型,存算一体。
CRDB 在一个事务性 KV 层上构建了 SQL 层。
CRDB 使用range partitioning,将 key 分为大概 64MB 大小的 chunck。每个 chunck 称为 Range。Range 之间的顺序是通过一个两层的 index 结构来维护的,这个结构在 system Range 中。有一个 Distribution Layer去检查哪些 Range 需要去处理 某个 subset of query。
Range 是 64MB 的大小,因为折让在不同node 之间移动更加容易。但是它又可以让连续的数据被存放在一起。Range 可以被合并或者分裂。
CRDB 使用 Raft进行 Replication。CRDB 使用 Range level 的 lease。在 Raft Group 中的一个 replica,一般是 Raft group leader 作为 leaseholder 的角色。这是唯一一个有权力去提供 up-to-date read 或者向 Raft group leader 提交写入的节点。因为所有的写入都通过 leaseholder 进行,所以读取可以减少 network 的开销。
【Q】我觉得这里有一个取舍,就是 Raft log 以及 index只是被用来做replication,还是也被用来做一致性的 replica read。
lease 的生命周期很自然要和 leaseholder 的生命周期绑定。所以 CRDB 会从 system Range 往各个 Range 的 leaseholder 维护一个 4.5s 的 interval 的心跳。然后 lease 需要每 9s 续期一次。如果某个 replica 发信啊 leaseholder 没有存活了,就会尝试获得 lease。
CRDB 通过 raft 来维护 lease,具体来说,就是会通过一个特别的 lease acquision raft command去获得 lease。为了避免两个 lease 在时间上是 overlap 的,lease acquisition 操作需要包含一个在请求时被认为是 valid 的 lease。
下面介绍了对于短期,或者长期的 failure node 的处理模式,这里略过了。
有几种 placement 的策略:
- GeoPartitioned Replicas 对于需要空间局部性的数据,一个 table 可以被分成多个 partition,一个 partition 包含多个 Range。这些 partition 会被分到同一个 region 中。这使得 intra-region 的读和写很快。适合需要数据监管的需求。
- GeoPartitioned Leaseholders Leaseholder 会被放在一个 region,另外的 replica 们会被放到别的 region 中。这个策略的 intra-region 读会好。同时也能承受regional failure。但是 cross region 写会比较差。
- Duplicated Indexes。索引也可以被固定到指定的region 中。By duplicating indexes on a table and pinning each index’s leaseholder to a specific region, the database can serve fast local reads while retaining the ability to survive regional failures. This comes with higher write amplification and slower cross-region writes, but is useful for data that is infrequently updated or cannot be tied to specific geographies.
TRANSACTIONS
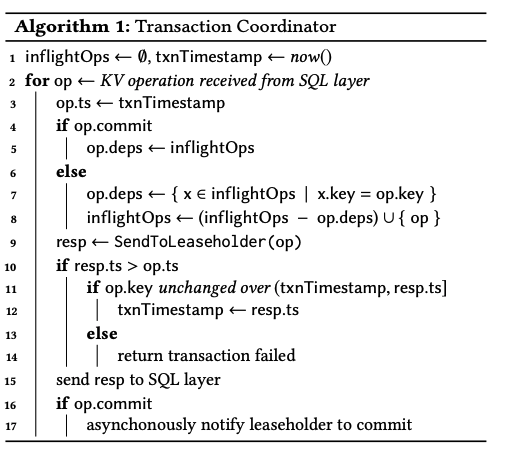
下面是coordinator 的角度看的事务算法。
在第二行中,需要发送很多的 KV 读写请求。为了减少 replicate 过程中的 write stall 现象,CRDB 主要引入了 Write Pipelining 技术以及 Parallel Commits 技术。
在第一行中,coordinator 会用 inflightOps 追踪所有还没被完全 replicate 的操作。
先介绍 Write Pipeling 优化。如果一个 op 并没有打算提交事务,那么就会通过 inflightOps 计算 op.deps,表示和这个 op 修改的 key 有 overlap 的,尚未完成的其他 op。如果这个 op 一来某个 inflight 的 op,那么就必须等待前面这个op 被 replicate 完毕,称为 pipeline stall 过程。否则,op 就可以立即被执行。所以写不同 key的多个 op 可以被 pipeline 地执行。anyway,在开始执行 op 后,会通过第8行更新 inflightOps。
然后,coordinator会发送一个 op 给 leaseholder 表示准备写入了,并在第 9 行处等待回复。这个回复中可能包含一个 ts,表示有另一个事务的读需要 leaseholder去调整 op.ts。这里我理解就类似于 TiKV 事务里面的 min_commit_ts 了。这个 coordinator 会尝试更新事务的时间戳。但是在这个之前,先要重新读一次 op.key,检查 value 有没有发生变化。如果变化了事务就需要失败重试,否则才能更新时间戳。
【Q】注意到,这里 CRDB 选择在事务提交前就往 KV 层写入数据了,在第 17 行,发现有 op.commit 的时候,才会异步通知 leaseholder 去提交事务。这和 TiKV 上现存的事务模型是不一样的。当然,后续有 pipelined txn model 用来支持大事务,这就类似于 CRDB 了。
下面是 Parallel Commit 的算法。下面,考虑事务提交的情况。朴素来讲,需要确保所有的 writes 都被 replica 之后,才能 commit。但是,PC 这个协议提供了一个 staging 的事务状态,which makes the true status of the ttxn conditional on whether all of its writes have been replicated. 这可以避免一轮额外的共识,因为 coordinator可以自由地 initiate the replication of the staging status in parallel with the verification of the outstading writes, which are also being replicated(第5行). 加入两个都成功了,这个 coordinator 就可以立即 ACK 这个 txn 是 commit 的了,也就是第 15 行。在事务结束之前,coordinator 还会异步记录 txn 的状态为 explicitlyy committed。这是处于性能的考虑。
下面是 leaseholder 需要执行的算法。
当 leaseholder 收到 coordinator 的 op 时,它首先检查自己的 lease 是否还 valid。然后,它需要对 op 中的所有的 key 都请求 latch。特别的,对于 op.deps 中的所有的 key,也要请求 latch。这样做的目的是为了实现两个 overlap 的 concurrent 事务之间的隔离。在 line 4,它检查 op.deps 中涉及到的写入是否已经完成了。如果要执行一次写入,他还需要保证 op.ts 是比所有冲突的读要高的,也就是在 line5 和 line6 要去尝试推高 op.ts,尽可能保证 txn 不被 invalidate 掉。【Q】注意,这就对应了算法1中的更新 op.ts 的部分。特别的,这是用来处理 RW 冲突的,对于 WW 冲突,就必须要重试了。
上面的初始检查结束之后,line7 会根据 op 生成 coomand 和 response。这些 command 就是 Raft command,response 是给 client 的返回。如果事务还没有被提交那么就可以直接返回给 coordinator,如 line9 和 line10,随后慢慢复制。在 line11 和 line12 就是执行状态机,并写入存储层的过程。在这个写入完毕之后,就会释放 latch。在 line13-15 会回复 coordinator,这里论文说的不是很明确。
在 line7 中可能遇到一些复杂的情况,比如遇到了其他事务的没有提交的写入。这些写入的时间戳可能和当前事务的时间戳相当接近,所以我们无法得到一个准确的 order。下面会讨论这种情况下如何保证原子性和隔离级别的。

atomic commit 是通过在 commit 的时候,才让这个事务的所有 writes 可见(provisional)来实现的。CRDB 将这些 provisional values 称为 write intents。一个 intent是一个MVCC KV pair,except that it is preceded by metadata indicating that what follows is an intent. 这个 metadata 指向一个txn record,实际上是一个每个事务独有的 key,里面存着当前事务的 disposition(pending、staging、committed 或者 aborted)。这个txn record 用来原子性地改变所有 intent 的可见性,并且随着这个txn 的第一次写入,被存在在同一个 Range 中。对于 long running 事务来说,coordinator 会定期心跳处于 pending 状态的 txn record,to assure contending transactions that it is still making progress.
当遇到一个 intent 的时候,一个reader 会读取 intent 的txn record。如果这个record 中显示txn 被提交了,reader 会将 intent 看做是一个 regular value,并且删除 intent 的 metadata,如果 txn 被删除了,intent 会被忽略,后续会被删除。如果是 pending,表示事务还在进行,reader 就会 block 等待事务结束。如果 coordinator node 挂掉了,contending txn 会最终发现 txn record 过期了,然后将它标记为 aborted。如果 txn 在 staging 状态,表示 txn 可能已经被 committed 或者 aborted了,但是 reader 不是很确定,此时,reader 会尝试 abort 掉事务。这里的方式是尝试阻止 replicate 事务的一个 write。但如果所有的 write 都被 replicate了,那事务就是事实上被提交了,我们就会承认这次提交。
下面是和 MVCC 相关的讨论。主要是解决之前提到的 commit ts可能太过于靠近,以至于无法区分的情况。
首先是 Write-read 冲突。也就是一个read 事务可能看到一个没有提交的具有更低的 ts 的 intent。这个时候,它就需要等待这个更早对的事务完成。这个等待是通过内存中的一个队列完成的。特别的,如果这个未完成的事务更大,则可以被忽略。
然后是 Read-write 冲突。也就是一个write 事务,它要以 t_a 写入 key。如果同一个 key 上此时有一个 t_b 大于等于 t_a 的读事务,那么这个写就不能执行,而是要更新自己的 t_a 到大于 t_b 的值。
然后是 Write-Write 冲突。一个 write 事务可能看到一个 ts 更小的没有完成的 intent。这个时候,类似于第一种情况,需要等待。WW 冲突可能引起 deadlock,比如不同的事务以不同的顺序写入同一组 key。CRDB 会使用分布式死锁检测算法从而在出现循环waiter的时候,abort 掉一个 transaction。
Certain types of conflicts described above require advancing the commit timestamp of a transaction. 为了满足 serializability,read ts 也需要被 advance,从而 match commit ts。
【Q】没太懂为啥需要 advance read ts。
如果我们能够证明在 t_a 到 t_b 时间内,没有 txn 要读取的数据被修改了,那么就可以将 read ts 从 t_a 推进到 t_b。当然如果不能证明,则需要 abort 事务。
为了能够确认这一点,CRDB 会在 txn 的 read set 中维护 key。一个 read refresh请求会被用来检查在给定的时间段中,key 有没有被更新。对应到算法一的 line11-14。这里面包含了要扫描整个 read set,然后检查哪些 MVCC value 是在这个interval里面的。This process is equivalent to detecting the rw-antidependencies that PostgreSQL tracks for its implementation of SSI [8, 49]. Similar to PostgreSQL, our implementation may allow false positives (forcing a transaction to abort when not strictly necessary) to avoid the overhead of maintaining a full dependency graph.
Advancing the transaction’s read timestamp is also required when a scan encounters an uncertain value: a value whose timestamp makes it unclear if it falls in the reader’s past or future (see Section 4.2). In this case we also attempt to perform a refresh. Assuming it is successful, the value will now be returned by the read.
Follow reads
通过 AS OF SYSTEM TIME 语句,允许从 Follower 副本读取过去的数据,当然事务只能是只读的。
一个非 leaseholder replica 在收到读取 T 时刻的请求时,需要知道没有后续的写入可以 invalidate read retroactivity。同样需要保证自己有所有必要的数据去 serve读请求。上面的这些条件表示,如果一个 follower 处理了一个 T 时刻的 follower read 请求,就不能再处理任何 T’ 小于等于 T 的 write 了。并且 Follower 必须追上 T 时刻所有可能影响 MVCC snapshot的 Raft log。
为此,每个 leaseholder 需要记录所有 incoming request 的 ts,并且阶段性的通告一个 closed timestamp,表示低于这个 ts 的所有写入后续都会被拒绝了。这个 ts 会通过 Raft 日志一起被复制。
Follower replicas use the state built up from received updates to determine if they have all the data needed to serve consistent reads at a given timestamp. For efficiency reasons the closed timestamp and the corresponding log indexes are generated at the node level (as opposed to the Range level).
每个 node 会记录自己和其他 node 的 latency。当一个 node 收到一个足够 old 的 ts(closed ts 通常要比当前时间晚 2s)的 read request 的时候,it forwards the request to the closest node with a replica of the data.
CLOCK SYNCHRONIZATION
CRDB 里面的每一个 node 都维护一个 hybrid logical clock,称为 HLC,是物理时钟和逻辑时钟的组合。逻辑时钟是基于 lamport 时钟的。同一个集群中的 HLC 允许有一个物理时间的 offset。默认值是 500ms 这是比较保守的。
- HLC 在 logical 部分提供了因果关系的追踪。这保护了 lease disjointness invariant 特性。也就是类似于 Spanner,对于每个 Range,每个 lease interval 都和其他的 lease interval 是 disjoint 的。This is enforced on cooperative lease handoff with causality transfer through the HLC and is enforced on non-cooperative lease acquisition through a delay equal to the maximum clock offset between lease intervals.
- HLC 提供了严格的单调性,无论是否重启。这是因为在重启后,会要求等待超过 maximum clock offset 的时间,然后再处理任何请求。这个特性保证了两个有因果关系的事务,并且如果是在同一个 node 上发起的,那么它们的 ts 能够反应实时的 order。
- HLC 提供了 self-stabilization,即使在存在 isolated transient clock skew fluctuation 的情况。As stated above, a node forwards its HLC upon its receipt of a network message. The effect of this is that given sufficient intra-cluster communication, HLCs across nodes tend to converge and stabilize even if their individual physical clocks diverge. This provides no strong guarantees but can mask clock synchronization errors in practice. 大概意思就是 intra-cluster 的消息比较多,所以这个时间能够最终收敛。
目前,我们已经讨论了 crdb 中的事务模型是如何提供 serializable 隔离的。但是 serializability 本身并没有讲述事务是如何在按照实际发生的顺序在系统中排序的,所以要讲述 consistency level。
在正常情况下,crdb 支持 single-key linearizability。也就是每个对指定 key 的 operation 都 appears to take place atomically and in some total linear order consistent with the real-time ordering of those operations. 在这个一致性下,stale read anomalies 是不会发生的。对于 loosely synchronized clock 也是这样的,只要这些 clock 在配置的 max clock offset 之内。
注意,crdb 并不支持 strict serializability,因为没有任何保证说 the ordering of transactions touching disjoint key sets will match their ordering in real time. 在实践中,这对 application 并不是一个问题,除非有一个 external low-latency communication channel between clients that could potentially impoct activity on the DBMS。
实现 single-key linearizability 特性是通过跟踪每个 txn 的 uncertainty interval 来实现的。在这个 interval 中,两个事务的 causal ordering 是不确定的。在它被创建时,一个事务就会被提供一个临时的 commit ts。这个 commit ts 一般是 coordinator 的 local HLC,因此它的 uncertainty interval 是 [commit_ts, commit_ts + max_offset]。
当一个 txn 遇到一个value onn a key 并且它的 ts 比自己的临时 commit ts 要更低的时候,它就会在读的时候自然地观察到,并且在写的时候,通过一个更大的 ts 去 overwrite 掉这个 value。如果 txn 有一个完全同步的 global clock,那么这样就已经满足 single-key linearizability 了。
但如果没有这样的 global clock,就需要考虑 uncertainty interval 了,因为 it is possible for a transaction to receive a provisional commit timestamp up to the cluster’s max_offset earlier than a transaction that causally preceded this new transaction in real time. 当一个事务遇到一个 value onn a key 并且它的 ts 是比自己的临时 commit_ts 要高,但是又在 uncertainty interval 里面,他就需要执行一次 uncertainty restart,moving its provisional commit timestamp above the uncertain value but keeping the upper bound of its uncertainty interval fixed.
This corresponds to treating all values in a transaction’s uncertainty window as past writes. As a result, the operations on each key performed by transactions take place in an order consistent with the real time ordering of those transactions.
到此为止,我们只是考虑了遵守了配置了的 max clock offset bounds 的情况。也需要考虑如果不遵守会有什么后果。
对于单个 Range,通过 Raft 来保证一致性,所以不论是否有 clock skew 都是线性一致的。但是,Range lease 允许 leaseholder 不通过 raft 直接返回 read 的结果,这就复杂了。比如,多个 node 都有可能认为自己持有某个 Range 的 lease,如果没有额外的保护,这就可能导致冲突的操作。
CRDB 有两种方式来防止:
- Range lease 包含一个 start 和 end 时间戳,一个 leaseholder 不能处理 MVCC ts 高于 lease interval 的读请求,不能处理 MVCC ts 在 lease interval 之外的写请求。先前讨论过的 lease disjointness invariant 保证了每个 lease interval 都和其他的不相交。
【Q】我不太清楚这的 end 时间戳和之前的 closed timestamp 是不是类似的东西。我理解至少有两点是不同的,首先,closed timestamp 会跟随 raft log 一起复制。其次,closed timestamp 是用来服务于 Follower read 的。
【Q】我理解这实际上是对于任意的 write,在所有时间中,只有唯一的 leaseholder 能够处理它。 - 每个写到 raft log 中的 write 都包含了 Range lease 的 sequence。对于一次成功的 replication,sequence number 会被和当前 active 的 lease 放在一起检查。如果它们不匹配,写入会被拒绝。这是因为 lease 的变化本来就会被写到 Raft 日志里面,只有一个 leaseholder 才能对 Range 做出改变。即使多个 nodes 都认为自己持有一个 valid 的 lease,也改变不了这个事实。【Q】我理解就是用 Raft 的特性去保证 lease 的独一性。如果 “term” 或者 “epoch”(无论你叫它什么)不匹配,那么就不能写入。
第一个方式保证了一个 incoming leaseholder 不会处理一个 write,如果它会 invalidate 一个 outgoing leaseholder 的 read。
第二个方式保证了一个 outgoing leaseholder 不会处理一个 write,如果他会 invalidate 一个 incoming leaseholder 的 write 或者 read。
加在一起,这些方式保证了即使在严重的 clock skew,甚至违背了 max clock offset bound 的情况下,CRDB 都能保证 serializable isolation。
【Q】我没懂这里在说什么。比如他说了 lease disjointness invariant 保证了 lease 不会相交,那为啥可能同时有两个 node 都觉得自己是 leaseholder?
虽然无论是否有 clock skew 都可以保证 isolation,但是超出 clock offset bounds 的 clock skew 就会破坏有因果关系的事务之间的 single-key linearizability 了。比如说,如果这些事务是从不同的 gateway nodes 中被发过来的,假如第二个 txn 的 gateway node 被分配了一个 commit_ts,它比第一个 txn 的 ts 落后超过了 max_offset,那么第一个事务所写入的值,就会在第二个事务的 uncertainty interval 之外。这就可能导致第二个事务 to read keys overlapping the write set of the first without actually observing the writes. Stale read 就是一个违反 Single Key lin 的情况,并且只有在 clock 在 offset bounds 中才能被避免。
【Q】这里我觉得 TiKV 得到线性一致的方式简单粗暴很多,通过禁止 leader 去乱序 apply,保证了 learner 和 leader 是看到一个顺序。然后通过 read index 得到的一个 index,就类似于“领导人完全性”的性质,只要我 apply 到了这个 index,就肯定按顺序 apply 到了所有这个 index 之前的 log 了。
【Q】但是,绕不开的话题还是如何识别谁是 Leader 或者 leaseholder。对于 Raft 只有一种 source of truth,就是尝试 propose 一条日志,但肯定代价太大了。但相比 CRDB 的 leaseholder,至少将 Leader 和 leaseholder 绑定提供了这么一种 source of truth。但是,TiKV 依旧需要依赖 NTP,从而确保所有节点看到的 leaseholder 的过期时间是接近的。
To reduce the likelihood of stale reads, nodes periodically measure their clock’s offset from other nodes. If any node exceeds the configured maximum offset by more than 80% compared to a majority of other nodes, it self-terminates.
LESSONS LEARNED
一些对 raft 的优化:
- 将 heartbeat msg 从 raft group 级别的降低为 node 级别的,对于不活动的 raft group,让它 hibernate
- joint consensus
CRDB 原来还支持 SI 的隔离级别。但是它默认使用 SERIALIZABLE 级别因为他们认为应用开发者不应该担心 write skew anomalies。然后crdb 的实现使得 SERIALIZABLE 的惩罚也不大。
因为 crdb 一开始是针对 SERIALIZABLE 设计的,所以他们想是不是可以移除 write skew 检查就行了。但后面发现,唯一能够在 si 下保证 strong consistency 的是悲观锁,比如 FOR SHARE 和 FOR UPDATE。因此,CRDB 需要对任意的 row updates 引入悲观锁,甚至是 SERIALIZABLE 事务。所以,CRDB 就不再真的实现它了。
【Q】这里没有说的很详细。我理解他说的 consistency 应该指的是 ACID 中的 C 了吧。
早期,crdb 会在每个 replica 上进行 evaluate 操作,然后再 apply。但是考虑升级的场景,可能新旧的 replica 在 evaluate 上是不一样的,因此每个 replica 上的数据也是不一样的了。因此,现在是先 evaluate,然后 propose 的是 evaluate 这个 request 的结果,而不是这个 request 本身。

