这篇文章中,包含 Greenplum、Aurora、Dynamo、WiscKey。
特别地,也会介绍 Titan 这个类似 WiscKey 的一个实现。
Greenplum
Greenplum: A Hybrid Database for Transactional and Analytical Workloads
Intro
Greenplum 类似于 Redshift、AnalyticDB、BigQuery 这样的 PB 级别的数据仓库。相比之下,像 CRDB、Amazon RDS 这种关系型数据库主要还是在 TB 阶段。
Client 和 coordinator 交互,coordinator 将任务下发到各个 segment 上。各个 segment 并行处理,并且可能会 shuffle 一些 tuple。
DML 可以在 worker segment 上被用来修改数据。
原子性通过 2PC 保证。
并发事务通过分布式快照保证。
Greenplum 支持 append-optimized column-oriented 表。支持多种压缩算法。这些表适合用来做 bulk read 和 buld write,也就是典型的 OLAP 负载。
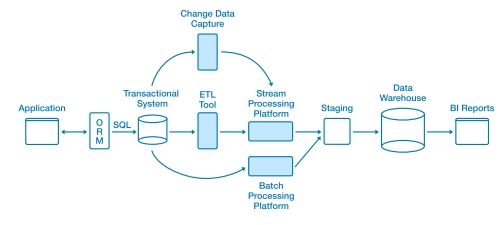
后面就自然演化出 HTAP 的需求,要求点查的响应要快,也要有 scalable 的 AP 能力。
GP 主要是三点:
- 并行的 data loading,且 ACID
- 减少点查的响应时间
- Resource Group,隔离用户在不同类型的 workload 的资源
GP 以 OLAP 为第一等公民。特别是对于小事务来说,2PC 是一个巨大的惩罚。Coordinator 会被施加很重的锁,以避免 distributed deadlock,这个设计限制性太大了。
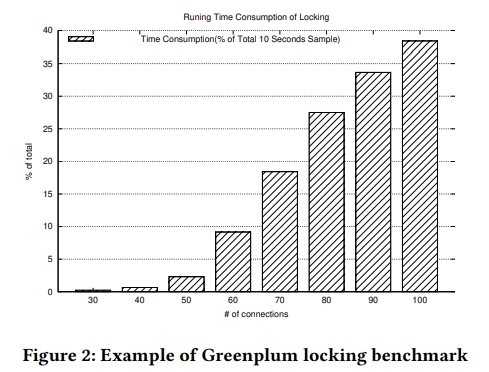
下面这张图的意思是对于一个 10s 的查询,在锁上面占用的时间的比例。随着并发度的提高,这个时间越来越不可接受。
GP 的贡献:
- 如何从 OLAP 转换成为 HTAP
- global deadlock detector
作用是减少了锁的开销,优化了 TP 的响应时间。同时不牺牲 AP。 - 对于一个 segment 上的事务只做 1PC
- 前面提到的 resource control
在 Relate work 中主要介绍了两种 HTAP 方案。第一种是从 OLTP 演进的,包含 Oracle Exadata、Aurora。另一种是从 NewSQL 演进的,例如 Spanner、CRDB、TiDB 和 F1。
MPP 架构
在整个数据库中,只有一个 coordinator segment。
一些 segment 会被作为 mirror 或者 standby(特指对 coordinator)存在,但不会参与到计算中。它们接受 WAL,并且回放。
GP 是 shared-nothing 的。使用各自的内存和 data directory,只通过 network 访问。
Distributed Plan and Distributed Executor
作为 shared-nothing 架构,在 join 的时候就需要在 segments 之间移动 tuples。
GP 引入了 Motion plan。Motion 将 plan 切分为更小的块,称为 slice,我理解就是子计划。每个 slice 被一个 process group 执行,这一 process group 称为 gang。
With the proposed Motion plan node and gang mentioned above, Greenplum’s query plan and the executor both becomes distributed. The plan will be dispatched to each process, and based on its local context and state, each process executes its own slice of the plan to finish the query execution. The described execution is the Single Program Multiple Data technique: we dispatch the same plan to groups of processes across the cluster and different processes spawned by different segments have their own local context, states, and data.
下图的上面部分是一个分布式查询计划,下面部分是这个计划的执行流程。在例子中有两个 segment。
The top slice is executed by a single process on the coordinator, and other slices are executed on segments. One slice scans the table and then sends the tuples out using redistributed motion. Another slice that performs hash join will receive tuples from the motion node, scan the student table, build a hash table, compute the hash join, and finally send tuples out to the top slice.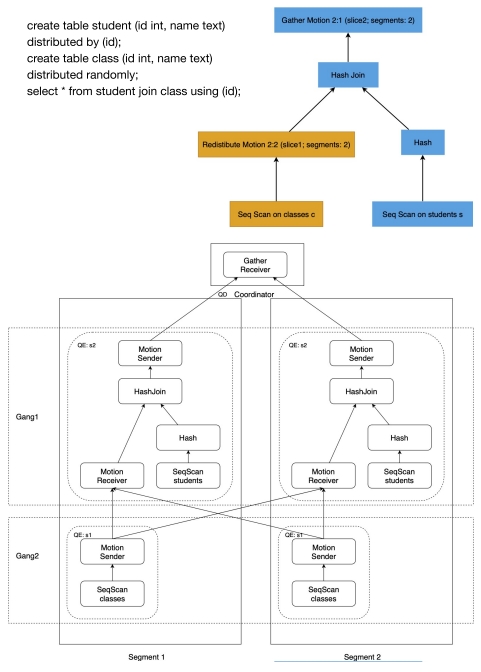
Distributed Transaction Management
GP 中,每个 segment 实际上是一个 PostgreSQL 实例。
为了保障 ACID 特性,GP 用了 2PC 和分布式快照。
Hybrid Storage and Optimizer
GP 支持 PSQL 原生的 heap table。这个 table 是一个行存,包含固定大小的 block,以及被多个 query 共享的 cache。
GP 自己添加了两种新表:AO-row 和 AO-column。AO 表示 append-optimized。AO 的访问模式更有利于 bulk IO,也就是 AP 的工作负载。
GP 的分区是在 root table 下新建更低层级的表来做的,这里就类似于 TiDB 的方案。不同的 partition 可以存在不同的表类型中,特别地,还支持一些外部存储,比如 HDFS、S3 等。
OBJECT LOCK OPTIMIZATION
这是 GP 的关键。核心是通过一个算法解决分布式环境下的 global deadlock 问题。
GP 会举例子来讲解。例子中有两个 int column c1 和 c2,c1 是 distributed ke。数据分布在三个 segments 上。
Locks in Greenplum
三种类型的锁:spin lock,LWLock,Object lock。
前两者是为了保护读写共享内存的,我理解实际上叫 latch 吧。主要还是聚焦 Object 锁。
和 PSQL 一样,lock mode 分为 8 个级别。
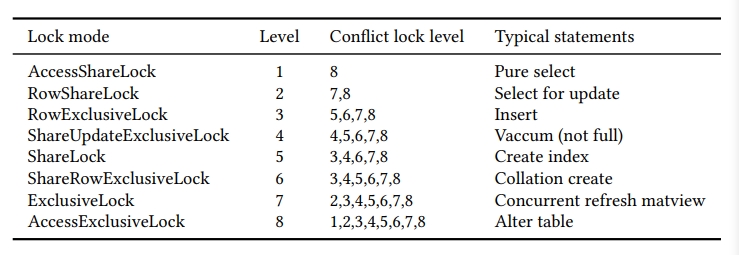
但是 MPP 数据库和 PSQL 的锁算法是有区别的,PSQL 锁逻辑不能发现或者解决 global deadlock。更具体来说,需要增加 DML 操作的 local level,保证事务是 serially 执行的。
在 GP 的早期版本是基于 PSQL 的,在事务比较多的时候,性能很差,因为只有一个事务能够对同一个 relation 进行 update 或者 delete。
Global Deadlock Issue
在诸如 GP 这样的分布式系统中,DML 语句的行为如下:
- 在 parse-analyze 阶段, the transaction locks the target relation in some mode.
- 在执行阶段,事务在 tuple 中写入自己的 id。This is just a way of locking tuple using the transaction lock.
在 PSQL 这样的单机数据库中,第一阶段一般是 RowExclusive 锁。所以它们是能够并发的,除非它们要写的是同一个 tuple,才会有等待。
这些 lock dependencies 会被存在每个 segment 的内存中,如果死锁发生了,就可以通过内存中的信息去解决。
但是 PSQL 的 lock deadlock handler 是不够的。如下图所示
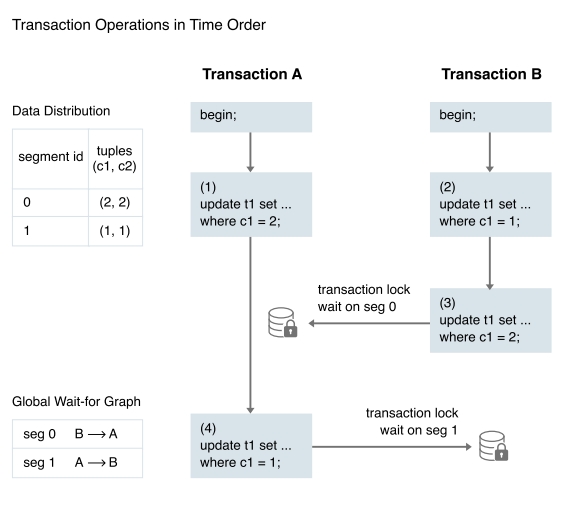
简单来说,是下面的时序关系:
- A 要写 segment 0 里面的一个 tuple (2, 2),持有的是 segment 0 的锁。B 要写 segment 1 里面的一个 tuple (1, 1),持有的是 segment 1 的锁。
- B 需要写刚才 A 写的那个 tuple,因为 A 还没有 commit 或者 abort,所以 B 得等。
- 同理,A 要写 B 刚才写的 tuple,A 也得等。
于是,segment 0 上的 B 在等 segment 1 上的 A。segment 1 上是类似的情况。无论是 segment 0 还是 1,它本地的 deadlock handler 都检测不到有 deadlock,这也就是一直在说的 global deadlock。
后面还举了一个更复杂的例子,我也不想看了。
在 GP 5 以及之前的版本,同一个 relation 上面的事务是串行执行的。并发度很差了,虽然肯定没有死锁。
Global Deadlock Detection Algorithm
GDD 要点:
- 在 coordinator segment 上启动一个 daemon
- daemon 定时收集每个 segment 上的 wait-for 图
- daemon 确定是否有 global deadlock 发生
- daemon 使用预定义的策略解决死锁
wait-for 图中,点表示事务,有向边 a -> b 表示 a 在等 b。这里会引入 deg(G)(V) 和 deg(i)(V) 分别表示 V 的 global out-degree 以及 i 的 local out-degree。
从不同 segment 收到的 wait-for 信息是异步的。
GDD 算法的核心是贪心,它会尝试 remove 掉可能在后续能执行的边,那么剩下来的边上可能就会发生 global deadlock。当然,这是不够的,算法的 recall 和 accuracy 都得是 1 才行。
这个时候,算法就需要在 coordinator 上面 lock 所有的 process,然后检查剩余的 edge 是否是 valid 的。如果这个时候一些事务已经结束了,GDD 就会 abort 掉这一轮的所有信息,sleep 一段时间,然后开启下一轮。
在 global wait-for 图中,有两种边:
- 实线边
表示这个 waiting 只会在持有锁的事务结束后才会消失。
比如说 when a relation lock on the target table in UPDATE 或者 DELETE 语句。
Such an edge can be removed only when the holding transaction is not blocked everywhere because based on the greedy rule we can suppose the hold transaction will be over and release all locks it holds.
例如 Xid lock、Relation lock closed with NO_LOCK。 - 虚线边
表示可以在事务还没结束的时候,这个锁就可能被 release 了。
For example, a tuple lock that is held just before modifying the content of a tuple during the execution of a low level delete or update operation. Such an edge can be removed only when the holding transaction is not blocked by others in the specific segment. This is based on the greedy rule we can suppose the hold transaction will release the locks that blocks the waiting transaction without committing or aborting.
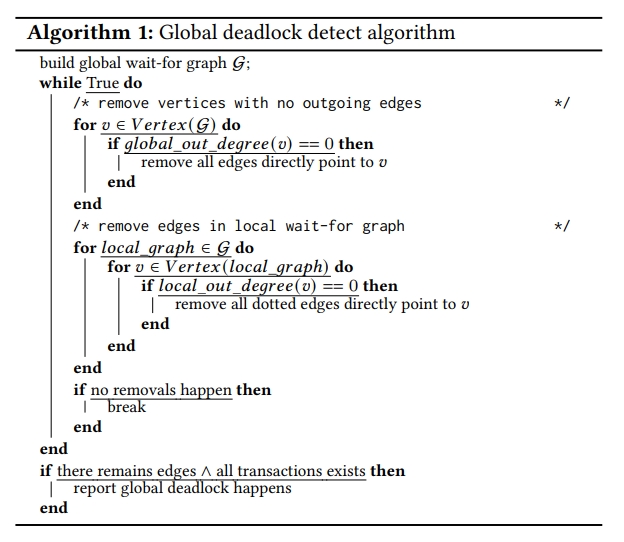
GDD 算法如下。
首先移除掉所有出度为 0 的 V。
然后扫描每个 local wait-for 图,删除掉所有指向出度为 0 的 V 的虚线边。
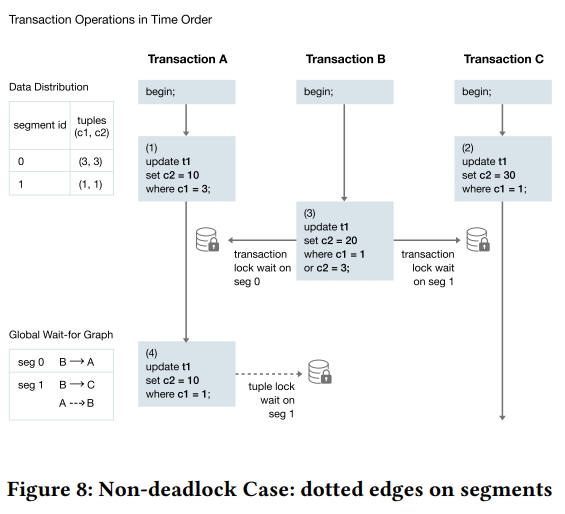
Demo
在下面的例子中,在前三步 B 会被 segment 0 上的 A 和 segment 1 上的 C 阻塞。在第四步,A 有试图 lock segment 1 上的 tuple,然后被 B 阻塞。
【Q】这里应该同时也会被 C 阻塞?
注意,这里的 A -> B 是一个虚线。【Q】Why?我理解可能是事务上的第一个锁是 xid 锁,后面的是 tuple 锁。
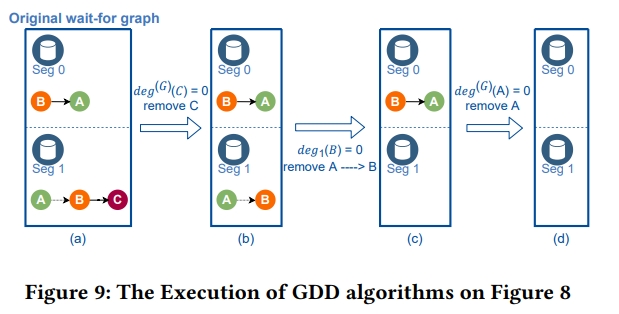
下面是 GDD 算法:
- 首先,C 的 global 出度是 0。因为 C 没有在等任何的事务。因此在移除掉 C 之后,得到 (b) 这张图。
- 发现 B 在 seg 1 上的出度是 0,所以可以移除所有指向 B 的虚线边,从而得到 (c) 这张图。
- 发现 A 的 global 出度是 0,移除掉 A 之后,可以得到 (d) 这张图。
- GDD 报告没有死锁。
DISTRIBUTED TRANSACTION MANAGEMENT
Aurora
Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases
Intro
认为随着扩容,IO 瓶颈变成了网络。特别是在存算分离下,变成了计算层和存储层之间的网络。因为计算节点通常是并行发送请求,所以网络问题还存在木桶效应。
有一些操作是同步的,比如如果 cache miss,读线程就会等待。checkpoint 以及 dirty page write 技术能够缓解,但也会引入 stall、context switch 以及 resource contention 问题。
另外,事务提交也是另一个问题。特别是在分布式环境下的 2PC 会更加有挑战性。
Aurora 的思想是更加激进地使用 redo log。它从一个 virtualized segmented redo log 抽象上构造的
We use a novel service-oriented architecture with a multi-tenant scale-out storage service that abstracts a virtualized segmented redo log and is loosely coupled to a fleet of database instances. Although each instance still includes most of the components of a traditional kernel (query processor, transactions, locking, buffer cache, access methods and undo management) several functions (redo logging, durable storage, crash recovery, and backup/restore) are off-loaded to the storage service.
三点优势:
- 由存储服务来负责容错以及自愈,数据库就可免受存储层的影响
他们说 failure in durability 可以被看做长期的 availablity 问题,一个 availablity 问题可以被看做长期的性能问题。 - 因为往存储写的是 redo log,所以能够大幅度减少 IOPS
- 将一些复杂但是重要的工作,比如 backup and redo recovery 从一次性的昂贵操作转变为连续的异步操作,并且这些操作分布在多个机器上的
这实际上让 crash recovery 变得非常快,并且这还不需要依赖 checkpoint 技术,也不会影响前台的处理。
DURABILITY AT SCALE
Replication and Correlated Failures
这里说的 instance 应该可以理解为计算层。Aurora 说这两个的生命周期不是一致的,计算层随着上下线,扩缩容,变化更大。
假如有 V 个副本,令读操作需要 Vr 票,写操作需要 Vw 票,那么:
- Vr + Vw > V
也就是至少有一个读节点能看到最近的写入。 - Vw > V / 2
这是在写入的时候,要避免冲突,形成多数。
所以,为了容忍单个节点的故障,可以选择 V 为 3,Vr 为 2,Vw 为 2。这个类似于 Dynamo,在 分布式一致性和分布式共识协议 中也讲解了为什么 Vr + Vw > V 并不足以能保证线性一致。
但是 Aurora 认为这是不够的,主要是如果一个 AZ 挂了,就会损失两个副本,这样就没有办法确认第三个副本是不是最新的了。Aurora 需要实现的是:
- 丢失一个 AZ 不影响写入能力
- 丢失一个 AZ 以及一个额外节点而不影响数据恢复能力
因此,它们使用了 V=6,Vr = 3,Vw=4 的模型。
Segmented Storage
通过缩短 MTTR 去减少可能出现 double fault 的窗口。
主要就是将数据库氛围 10GB 的 Segment,每个 Segment 按照六副本复制,会被复制到 3 个 AZ 中,每个 AZ 两个副本。目前 Aurora 支持最大 64TB 的数据库。
10 GB 的 segment 可以在 10s 内被修复,基于一个 10Gbps 的网络。
Operational Advantages of Resilience
THE LOG IS THE DATABASE
The Burden of Amplified Writes
主要是为了维持多副本,IO 就会显著变高。IO 变高会导致系统中的同步阻塞点变多。这里提到,Chain replication 能够减少网络开销,但是链式复制引入了更多的同步。
在传统数据库中,数据被写入到 data page 中,也被写到 redo log 中。每个 redo log 包含了前像和后像之间的 diff。
下图是如果要维护一个传统的 MySQL 镜像需要进行的 replication 的数据规模。
这里 double write 指的是 MySQL 在刷脏页的时候,如果中途发生宕机,可能有一个页面只写了一般,从而丢失数据的情况。因为 redo log 记录的是 diff 而不是 page 本身的数据,所以无法通过 redo log 恢复。double write 机制是先把这些页面顺序地写到磁盘上连续的一些页中(128页 * 16K=2MB),然后再刷到实际的位置中。这样可以从第一次写的地方恢复最近一次刷脏的页面。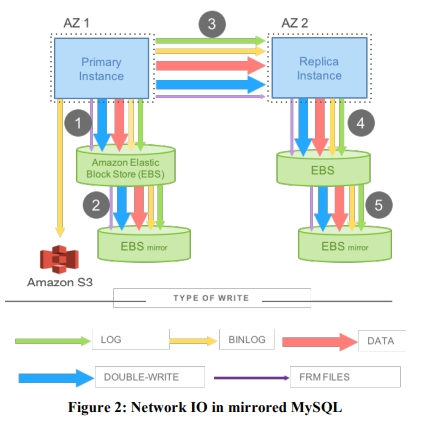
从分布式系统角度看,这个模型是一个 4/4 write quorum,对 failure 和离群点性能更敏感。
Offloading Redo Processing to Storage
传统数据库中惠使用 log applicator 去将 redo log 应用到前像上从而产生后像,事务提交至少需要 redo log 被持久化。Aurora 在数据库层面,没有后台写、checkpoint、cache evection。log applicator 会被下推到存储层,从而可以后台地、异步地去生成 database page。
当然,从头开始生成的代价是昂贵的,所以我们会在后台持续物化 database page,来避免每次都重新生成。当然,这个物化是完全可选的,因为 the log is the database。
Note also that, unlike checkpointing, only pages with a long chain of modifications need to be rematerialized. Checkpointing is governed by the length of the entire redo log chain. Aurora page materialization is governed by the length of the chain for a given page.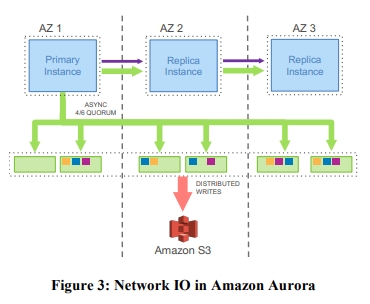
下面是一个显著的性能对比。
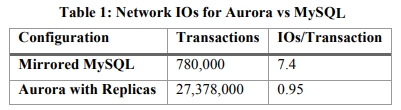
在存储层进行日志复制的工作实际上能减少 crash recovery 时间,并且消除 checkpoint、后台 data page 写入、backup 导致的 jitter。因此,提高了可用性。
原因如下。在传统数据库中,在一次 crash 之后,系统必须从最近的 checkpoint 开始回放 redo log。In Aurora, durable redo record application happens at the storage tier, continuously, asynchronously, and distributed across the fleet. Any read request for a data page may require some redo records to be applied if the page is not current. As a result, the process of crash recovery is spread across all normal foreground processing. 在数据库重启的时候,无需进行任何的操作,也没有额外的等待。
Storage Service Design Points
Aurora 设计的信条是减少前台写入的延迟。因此,它将大部分的 storage processing 移动到了后台。
Given the natural variability between peak to average foreground requests from the storage tier, we have ample time to perform these tasks outside the foreground path. We also have the opportunity to trade CPU for disk.
例如,在存储节点忙于前台写入任务的时候,就没有必要进行 GC,除非磁盘要爆了。
在 Aurora 中,后台处理和前台处理是负相关的。而传统数据库中,后台写 page 以及 checkpoint 的操作,和前台负载是正相关的。如果引入 backlog 机制,就需要限制前台的活动,从而避免队列越积压越长。相反地,在 Aurora 中,如果一个节点积压卡死了,可以通过 4/6 Quorum 模型来轻松处理:这个节点会被标注为一个慢节点,但是不影响整个系统运行。
Let’s examine the various activities on the storage node in more detail. As seen in Figure 4, it involves the following steps:
- (1) receive log record and add to an in-memory queue
- (2) persist record on disk and acknowledge
- (3) organize records and identify gaps in the log since some batches may be lost
- (4) gossip with peers to fill in gaps, (5) coalesce log records into new data pages, (6) periodically stage log and new pages to S3
- (7) periodically garbage collect old versions
- (8) periodically validate CRC codes on pages.
注意,上述的每一步都是异步的。只有 1 和 2 属于前台写入路径中,从而可能影响到性能。
THE LOG MARCHES FORWARD
Solution sketch: Asynchronous Processing
每个 log record 都有一个对应的 LSN,它是单调递增的。通过它可以避免 2PC,which is chatty and intolerant of failures。
因为每个存储节点可能缺少一些 log record,所以它们会和 PG 中的其他成员 gossip,尝试 fill the holes。
下面这个不知道具体指的是什么
The runtime state maintained by the database lets us use single segment reads rather than quorum reads except on recovery when the state is lost and has to be rebuilt.
The database may have multiple outstanding isolated transactions, which can complete (reach a finished and durable state) in a different order than initiated. Supposing the database crashes or reboots, the determination of whether to roll back is separate for each of these individual transactions. The logic for tracking partially completed transactions and undoing them is kept in the database engine, just as if it were writing to simple disks.
但是在重启后,在数据库能够访问存储前,存储服务能够执行自己的 restore 逻辑。在恢复的时候,并不是关注事务,而是关注数据库能够看到一致性的存储视图。
存储服务应决定一个最大的 LSN,称为 VCL(Volume Complete LSN)。在存储恢复过程中,所有 LSN 大于 VCL 的日志都需要被截断。数据库可以进一步标记一个 CPL(Consistency Point LSNs)从而进一步截断日志。我们定义 VDL(Volumn Durable LSN)为所有副本中最大的 CPL,并且要小于等于 VCL。然后截断 LSN 大于 VDL 的所有日志。比如,即使我们有一份完整的直到 LSN 1007 的数据,但是数据库定义了 CPL 分别是 900/1000/1100,这样的话必须 truncate 到 1000。也就是 we are complete to 1007, but only durable to 1000.
因此,完整性和持久性是不同的,CPL 可以被看做一种必须被按序 accept 的存储层事务。如果客户端不关注这些区别,就可以将所有日志标志为 CPL。在实际应用时,数据库和存储服务的交互如下:
- 数据库层的事务被分为多个 MTR,这些 MTR 是有序的,并且必须要原子地被执行
- 所有的 MTR 由多个连续的 Log Record 组成
- MTR 的最终的 Log Record 是一个 CPL
在恢复的时候,数据库询问每个 PG 的 durable point,并用它来构造 VDL。
Normal Operation
Writes
In the normal/forward path, as the database receives acknowledgements to establish the write quorum for each batch of log records, it advances the current VDL.
分配 LSN 的规则是不能分配比 VDL+LAL 还大的 LSN。VDL 就是目前的 VDL,LAL 是一个常数,称为 LSN Aoolocation Limit,目前等于 10m。这个限制让数据库不会比存储系统超前太多。这样避免当存储或者网络跟不上的时候,后台压力过大导致写入阻塞。
注意,每个 Segment 只会看到对应 PG 的一个 log record 的子集。每个 log record 会附有一个后向指针,指向这个 PG 的前一条 log record。
These backlinks can be used to track the point of completeness of the log records that have reached each segment to establish a Segment Complete LSN(SCL) that identifies the greatest LSN below which all log records of the PG have been received. The SCL is used by the storage nodes when they gossip with each other in order to find and exchange log records that they are missing.
Commits
当客户端提交一个事务的时候,线程会记录一个 commit LSN,然后将它放到事务提交等待队列中,然后就继续其他工作。这等价于 WAL 协议:当且仅当最新的 VDL 大于等于 commit LSN 的时候,事务就提交完成了。
随着 VDL 的推进,数据库识别出这些已经提交完成了的事务,通过单独的线程将提交确认返回给正在等待的客户端。而之前说的工作线程依旧不会做这样的事情,它只是不停地 pull 其他的请求,然后处理。
Reads
Aurora 中也有一个 buffer cache。在传统数据库中,从 buffer cache 中 evict page,如果此 page 是个脏页,那么就会先 flush,然后再在 buffer cache 中替换这个页面。Aurora 并没有这种 evect 机制,但是也保证 cache 中的数据页一定是最新的版本。Aurora 的保证是只有在 page LSN 大于等于 VDL 的时候,才会去 evict 这个 page。其中 page LSN 表示最新一次对这个 page 修改的 log record 的 LSN。这个 protocal 保证了:
- 所有对这个 page 的修改都被持久化了
- 在 cache miss 的时候,只需要通过当前的 VDL 请求当前 page 的 version,就可以获得最新的 durable version
大部分时候的读取都不需要 read quorum。从磁盘读取时,构造一个 read-point,表示读取时候的 VDL。The database can then select a storage node that is complete with respect to the read point, knowing that it will therefore receive an up to date version. A page that is returned by the storage node must be consistent with the expected semantics of a mini-transaction (MTR) in the database. Since the database directly manages feeding log records to storage nodes and tracking progress (i.e., the SCL of each segment), it normally knows which segment is capable of satisfying a read (the segments whose SCL is greater than the read-point),所以可以向一个有足够数据的 segment 发送读请求。
假设数据库知道所有的 outstanding reads,他就计算任意时间点每个 PG 上的 Minimum Read Point LSN。If there are read replicas the writer gossips with them to establish the per-PG Minimum Read Point LSN across all nodes. 这些值称为 Protection Group Min Read Point LSN(PGMRPL),代表了一个 low watermark,这个 PG 上低于这个 mark 的所有 log record 都是不必要的了。换句话说,没有 read-point 低于 PGMRPL 的 read page 请求了。因此,数据库可以 advance the materialized pages on disk by coalescing the older log records and then 安全地 GC 掉它们。
实际的并发控制协议是在数据库中执行的,就好像在使用本地存储一样。
Replicas
一个共享存储卷上可以挂一个写节点以及15个读节点。【Q】不是很清楚只能挂在一个写节点是怎么做到 Vw = 4 的。
为了减少 lag,日志流在送给存储节点的同时,也会送给所有的 read replica。【Q】这个 read replica 是啥?是不是指的一种特殊类型的只读节点?
在 reader 中,数据库会消费 log 流,如果这个 log record 指向了 buffer cache 中的一个 page,就使用 log applicator 去 apply 这个特定的 redo 操作到 cache 中。否则(也就是如果不指向的话),就丢掉这个 log record。
注意,从 writer 的角度来看 replicas 是异步地消费这些 log record 的。而 writer 在处理用户的事务提交的时候,也是不管 replica 的。因此,就需要引入两条 replica 的规则:
- 只有 LSN 小于等于 VDL 的日志才能被 apply
- 属于同一个 single mini-transaction 的 log record 要被原子的 apply
这样才能看到一个一致的视图
在实践中,每个 replica 落后 writer 只有 20ms 左右。
Recovery
A great simplifying principle of a traditional database is that the same redo log applicator is used in the forward processing path as well as on recovery where it operates synchronously and in the foreground while the database is offline. We rely on the same principle in Aurora as well, except that the redo log applicator is decoupled from the database and operates on storage nodes, in parallel, and all the time in the background. Once the database starts up it performs volume recovery in collaboration with the storage service and as a result, an Aurora database can recover very quickly (generally under 10 seconds) even if it crashed while processing over 100,000 write statements per second.
Dynamo
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
Intro
In this environment there is a particular need for storage technologies that are always available. AWS 对可用性的要求很高。
treats failure handling as the normal case without impacting availability or performance.
Dynamo is used to manage the state of services that have very high reliability requirements and need tight control over the tradeoffs between availability, consistency, cost-effectiveness and performance.
Dynamo 用了一些经典的技术达到高可用性和可扩展性:
- 一致性哈希
- object versioning 实现一致性
给的论文是 Lamport clock - quorum-like technique 保证一致性,以及 decentralized replica synchronization protocol
- 基于 gossip 的分布式 failure 检测和 membership protocol
它的一个贡献是介绍如何评估不同的技术对于搭建一个高可用性的最终一致的 KV 存储的作用,以及这个系统最终的适用性。
BACKGROUND
对关系型数据库的评论:
- 很多需要持久化状态的服务只需要主键,不需要 rdbms 的复杂功能
- rdbms 的 replication 性能有限,牺牲 availbility 换 consistency。在 scale-out 和 smart partitioning 这一款不是很好
System Assumptions and Requirements
查询模型:简单的主键读写。1MB 左右的 blob。没有操作跨越多个 data items。
ACID 性质:不提供任何 I 的保证,只允许 single key updates。
Efficiency:满足 SLA。
Service Level Agreements (SLA)
To guarantee that the application can deliver its functionality in a bounded time, each and every dependency in the platform needs to deliver its functionality with even tighter bounds.
客户和提供商会签 SLA 契约,里面包含了客户期望某个 API 的 request rate distribution,以及这些条件下的 service latency。比如,某个 API 在多少 QPS 下,99.9% 的请求的耗时都在 300ms 内。
下面讲述了为什么选择 P99.9 作为 SLA 的指标,就不翻译了。这个做法是基于一个 cost-benefit analysis 得到的。
A common approach in the industry for forming a performance oriented SLA is to describe it using average, median and expected variance. At Amazon we have found that these metrics are not good enough if the goal is to build a system where all customers have a good experience, rather than just the majority. For example if extensive personalization techniques are used then customers with longer histories require more processing which impacts performance at the high-end of the distribution. An SLA stated in terms of mean or median response times will not address the performance of this important customer segment. To address this issue, at Amazon, SLAs are expressed and measured at the 99.9th percentile of the distribution.
Dynamo 的一个主要的设计考虑是让用户来控制系统的特性比如 consistency 和 durability,并且让服务自己去在 functionality、performance 和 const-effectiveness 之间权衡。
Design Considerations
首先提了下 CAP 理论。那么对于容易发生机器和网络故障的系统来说,可用性可以通过 optimistic replication 技术提高。这种技术需要发现并且 resolve conflict changes。这个过程包含两部分:
- when to resolve them
- who resolves them
when
很多关系型数据库在写入阶段处理,这样 read 的复杂度更低。这种情况下,如果写入不能到达所有或者大多数 replica 时,会被拒绝。
另一方面,Dynamo 面向一个 “always writeable” 的 data store。所以,Dynamo 会将 conflict resolution 推到 read 阶段,让 write 不被拒绝。
who
如果让 data store 来做,那么选择就很有限。一般来说,只能用诸如 last write wins 这种 simple polocy。
另一方面,因为应用程序知道 data schema,所以更加适合。比如应用程序维护了客户的购物车,在遇到冲突的时候,可以选择 “merge” 购物车的内容。
另外的一些 Key priciples
Incremental scalability: Dynamo should be able to scale out one storage host(后面简称为 node) at a time.
Symmetry: 每个节点的职责应该是相同的。目的是简化系统交付和运维。
Decentralization: 在过去,集中化控制导致了 outage,我们想避免。这产生了更简单,易于扩展,并且可用性更好的系统。
Heterogeneity: 系统要能利用基础设施的异构性。比如添加了更牛逼的节点之后,系统能够适配,比如给它更多的活这样。
RELATED WORK
Peer to Peer Systems
Distributed File Systems and Databases
讨论
Dynamo differs from the aforementioned decentralized storage systems in terms of its target requirements.
- First, Dynamo is targeted mainly at applications that need an “always writeable” data store where no updates are rejected due to failures or concurrent writes. This is a crucial requirement for many Amazon applications.
- Second, as noted earlier, Dynamo is built for an infrastructure within a single administrative domain where all nodes are assumed to be trusted.
- Third, applications that use Dynamo do not require support for hierarchical namespaces (a norm in many file systems) or complex relational schema (supported by traditional databases).
- Fourth, Dynamo is built for latency sensitive applications that require at least 99.9% of read and write operations to be performed within a few hundred milliseconds. To meet these stringent latency requirements, it was imperative for us to avoid routing requests through multiple nodes (which is the typical design adopted by several distributed hash table systems such as Chord and Pastry). This is because multihop routing increases variability in response times, thereby increasing the latency at higher percentiles. Dynamo can be characterized as a zero-hop DHT, where each node maintains enough routing information locally to route a request to the appropriate node directly.
SYSTEM ARCHITECTURE
System Interface
- get(key)
返回一个对象。如果有冲突版本,就返回一个对象列表。还会返回 context,从后文来看,无论返回的是对象还是对象列表,都会返回一个 context 实例。 - put(key, context, object)
context 对调用者透明,包含了系统元数据比如 version。
Partitioning Algorithm
优化了基础的一致性哈希:每个 Dynamo 节点映射到环上的多个点。
原因是存储的硬件是异构的,厉害的人可以做更多的事情。所以 Dynamo 引入了 virtual node。一个 dynamo node 可以管理多个 virtual node。
虚拟节点的好处:
- If a node becomes unavailable (due to failures or routine maintenance), the load handled by this node is evenly dispersed across the remaining available nodes.
- When a node becomes available again, or a new node is added to the system, the newly available node accepts a roughly equivalent amount of load from each of the other vailable nodes.
- The number of virtual nodes that a node is responsible can decided based on its capacity, accounting for heterogeneity in the physical infrastructure.
Replication
每个 key k 会被分配到一个 coordinator node 上。coordinator 不仅会自己存储 key,而且会将它们复制到顺时方向的后 N-1 的 node 上。所以,每个 node 实际要存储 N 个 node 上的数据。比如下图中的 node D 需要存储 (A, D] 上的数据。
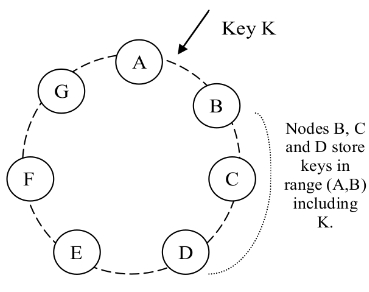
对于每一个 key,它被存储在多个 node 上,这些 node 形成一个 preference list。Section 4.8 会讲到如何维护这个表,现在需要知道的是为了处理 node failure 的情况,这个列表里面可能存放超过 N 个 node。
另外,使用 virtual node 的时候,可能根本没有 N 个 dynamo node 存储这 N 个 virtual node。比如一个 dynamo node 上存了几个 virtual node。【Q】我觉得也太扯了,一个 key 在同一个机器上存几份,即使是集群比较早期的状态,意义何在?Dynamo 也意识到了这个问题。为了避免这个问题,preference list 在选择节点的时候会跳过一些位置,确保 list 里面的节点在不同的物理节点上。
Data Versioning
一个 put() 可能在被 apply 到所有 node 之前就返回给 caller 了。这会导致后续的 get() 操作返回一个比较旧的 object。 如果没有网络问题,那么传递更新的耗时是有个上限的,但如果服务器宕机了,或者网络分区,那么更新就不能够及时到达所有的 replica。
很多应用程序是能够容忍这个 inconsistency 的。比如对于 shopping cart 来说,如果最新的版本没有拿到,并且客户又是基于一个旧版本进行的修改,那么这个修改依旧是有意义的,并且要被保留。当然这种保留并不是去覆盖,而更可能是 merge。注意,无论是添加到购物车,还是从购物车删除,对于 Dynamo 而言都是 put 操作。
Dynamo 将所有修改视为一个新的 immutable 的版本。也就是说允许一个对象在同一时间有多个版本。一般情况下,新版本跟随旧版本,此时系统能够知道谁是 authoritative version,我们称之为 syntactic reconciliation。但是 version branching 可能发生,比如 concurrent update 的时候出现了 failure。在这种情况下,系统不能处理,client 需要 reconcile,从而将多个 branch 坍缩回单个 version,称为 semantic reconciliation。比如 merge 购物车这样。当然,
Dynamo 使用向量时钟。一个向量时钟是一个 (node, counter) 列表。一个向量时钟和每个 object 的每个版本相关联。可以通过向量时钟判断两个 version 之间的因果性。如果在第一个 object 上的 vector clock 都不大于第二个 clock,那么第一个就是第二个的祖先。否则,就是冲突状态,需要 reconciliation。 这样 “add to cart” 操作就永远不会被丢掉,但是 deleted items can resurface.
It is important to understand that certain failure modes can potentially result in the system having not just two but several versions of the same data. Updates in the presence of network partitions and node failures can potentially result in an object having distinct version sub-histories, which the system will need to reconcile in the future. This requires us to design applications that explicitly acknowledge the possibility of multiple versions of the same data (in order to never lose any updates).
Dynamo 中,如果 client 需要更新一个 object,就需要指定基于哪个 version 更新。这是通过从上一次 read 时候获得的 context 得到的。在处理一个 read 请求时,如果 Dynamo 可以访问多个 branch,并且不能 syntactically reconciled,就会返回所有叶子节点上的对象,以及对应的 version information。使用这个 context 的 update 会被认为是已经 reconcil 了 divergent 的 version,并且所有的 branch 都坍缩回到一个单一的 version。
下面是一个 demo。Sx、Sy、Sz 都是节点。
- Sx 处理写入,会自增自己的 seq,然后用它来创建数据的 vector clock,因此系统中有了对象 D1 以及关联的时钟 [(Sx, 1)]
- 现在 client 又更新了对象,假如说又是 Sx 来处理了,那么系统中就有了 D2 和它的关联时钟 [(Sx, 2)]
注意,D2 “decendant” 了 D1,所以 overwrite 了 D1,当然有的 replica 可能认为 D1 还在,也就是没见到 D2。 - 不如假设此时 client 又更新了,这时候 Sy 来处理了。此时得到 D3 和 [(Sx, 2), (Sy, 1)]
显然这里 Sy 知道了 D2 的存在。 - 假设后续另一个 client 读到了 D2,然后进行了更新,由 Sz 来处理。得到了 D4 和 [(Sx, 2), (Sz, 1)]。
此时,一个能看到 D1 和 D2 的 node,在收到 D4 和它的时钟之后,可以发现 D1 和 D2 是可以被覆盖的。但是如果一个节点只看到了 D3,在收到 D4 之后会发现 D3 和 D4 之间没有因果关系。这个时候,两个数据都要保留,然后给 client 在下一次读的时候做 semantic reconciliation。
假设某个 client 同时读到了 D3 和 D4,此时 context 是 [(Sx, 2), (Sy, 1), (Sz, 1)]。如果这个 client 执行了 reconciliation,并且 Sx coordinate 了这个 write(也就是 client 处理完是 Sx 负责的写入),Sx 就会更新自己的 seq,所以新的 D5 的 clock 就是 [(Sx, 3), (Sy, 1), (Sz, 1)].
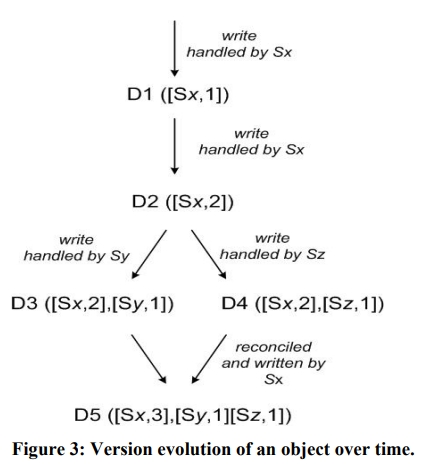
Vector clock 的一个问题是它可能会变大,特别是有很多 server 对同一个 object 操作的时候。但是在实践中并不经常发生,因为写入通常是由 preference list 里面的 top N nodes 中的某一个处理的。在网络分区的时候,可能是某个不在 top N nodes 里面的节点处理,从而导致 vector clock 列表变长。在这种情况下,Dynamo 有一个 truncation scheme: 对于每个 (node, counter) 对,记录一个 Timestamp,表示上一次这个 node 更新的时间。当这个 vector clock 中的 (node, pair) 对的数量超过一个阈值,比如 10 的时候,最老的 pair 就会被移动出去。
当然这个会导致 reconciliation 的时候的一些不便利的情况,比如 decendant relationship 就不能被准确推断出来。但反正生产环境也没发现有这个问题。
Execution of get () and put () operations
Dynamo 的任何 storage 节点都可以接受 client 的 get 和 put 请求。有两种选择 node 的方式:
- 通过一个通用的 load balancer
- 如果 client 知道 partition 的信息,就可以直接请求 coordinator node
第一种方式不需要了解 Dynamo 的实现,第二种可以避免额外一次的转发。
处理读写操作的节点是 coordinator。通常是 preference list 里面 top N nodes 的第一个。
读和写会涉及 preference list 中的前 N 个健康的 node。如果有 node 处于 failure 或者网络分区状态,那么 preference list 上更低 rank 的 node 就会被访问。
Dynamo 使用 RWN 协议来管理一致性。
Handling Failures: Hinted Handoff
介绍了 Sloppy Quorum 的方案。虽然所有的读写都需要在使用 preference list 上的 top N 健康 nodes。但是它们并不一定是顺着一致性哈希那个环来的 N 个。
Consider the example of Dynamo configuration given in Figure 2 with N=3. In this example, if node A is temporarily down or unreachable during a write operation then a replica that would normally have lived on A will now be sent to node D. This is done to maintain the desired availability and durability guarantees. The replica sent to D will have a hint in its metadata that suggests which node was the intended recipient of the replica (in this case A). Nodes that receive hinted replicas will keep them in a separate local database that is scanned periodically. Upon detecting that A has recovered, D will attempt to deliver the replica to A. Once the transfer succeeds, D may delete the object from its local store without decreasing the total number of replicas in the system.
Dynamo 通过 Hinted Handoff 摆正即使有节点临时故障,读写请求也不会 fail。
Handling permanent failures: Replica synchronization
一些场景中,当 hinted 副本移交回原 node 之前,这个副本就不可用了,这影响持久性。Dynamo 使用一个 anti-entropy 的 replica synchronization protocol 去做到这一点。
Dynamo 使用 Merkle tree 去发现不一致。这棵树是有关哈希值的,叶子节点是每个 key 的哈希值。上层的节点是它们各自孩子的哈希值。Merkle 树可以独立检查每个分支,而不需要下载整棵树下来。
Merkle 树还能帮助减少传递的数据量。这是因为它的性质,比如如果两个树的 root 上存的 hash 是相等的,那么两棵树就是相等的。因此,就不需要传输这些数据了。如果不相等,就继续往下比较,看看是哪里的问题。
Dynamo 对 Merkle 树的具体用法是,每个 node 上为每一段 key-range(对于一个 virtual node 的范围)维护一棵独立的树。因此,node 之间是可以比较 key range 的。
当有成员变更的时候,有些 key-range 可能会变,因此对应的 Merkle tree 要重新计算。
Membership and Failure Detection
Ring Membership
管理员通过命令行或者 Web UI 的方式发起一个 membership change 命令。这个命令也会被写入 Dymano 的存储。所有的成员变动会形成历史记录。Dynamo 使用 gossip 算法来 propagate 成员变动消息,维护一份最终一致视图。
当一个 node 启动时,它会扫描一致性哈希空间中的 virtual nodes 称为 token,它会选出一些,然后 maps nodes to their respective token sets.
这个 mapping 信息是存在磁盘上的,一开始只有本地的节点,以及 token set。节点和 token set 的映射是在和 membeiship change 一起 reconcil 的。因此,partitioning 和 placement 信息也会被 propagate,让每个 storage node 都了解 token range 信息。因此,每个 node 都能把读写请求 forward 到正确的节点集合中。
External Discovery
上述的机制可能导致暂时的逻辑分裂。
比如管理员先添加了 node A,然后立即添加了 node B,这个时候 A 和 B 都是哈希环的成员,但是却不能立即感知到对方。
因此 Dynamo 加入了种子节点,这些节点是通过外部的机制直接指定的,对所有的节点都是可知的。因为最终所有的 node 都会和种子节点通信,因此逻辑分裂是不太可能的。
种子节点可以通过静态文件,或者配置服务来获得。
Failure Detection
如果用户的请求是持续发过来的,node A 就能够快速发现 node B 不能响应了,当 B 开始无法回复一个 message 的时候。
In the absence of client requests to drive traffic between two nodes, neither node really needs to know whether the other is reachable and responsive.
Dynamo 早期有一个 decentralized failure detector 去维护一个 globally consistent view of failure state。但后面发现,explicit node join and leave 方案下,就不再需要这个 global view 了。这是因为通过这个机制,node 就能知道哪些 node 永久上线或者下线了。对于临时的 node failure,当哪个节点连不上的时候,就会独自发现了。
Adding/Removing Storage Nodes
当一个新的 node 比如 X 被加入到系统之后,它被分配一系列 token。这些 token 在 ring 上是散落分布的。此时,对于每个 token,有小于等于 N 个 node 已经在管理这 token 对应的 key-range 了。这些 node 中有一些就不会再管理了,要把 key-range 转给 X。
比如,X 加入 A 和 B 中间,这样 X 就会处理 (F, G], (G, A] 和 (A, X] 之间的 key 了。结果 B、C、D 节点就不需要负责对应的 range 了。Therefore, nodes B, C, and D will offer to and upon confirmation from X transfer the appropriate set of keys. When a node is removed from the system, the reallocation of keys happens in a reverse process.
通过在 source 和 destination 之间增加一个 confirmation round,可以避免 destination node 不会收到 duplicate transfers。
IMPLEMENTATION
前面略。主要介绍下 write coordination。
如前面所说,write 请求会被某个 top N nodes 来 coordinate。尽管我们希望去选择 first node,从而将所有的 write 都写到同一个地方,但这会导致不平衡的 load distribution。因为请求本身就不一定是均匀分布的。因此,preference list 中 top N 的任意节点都是可以被返回的。特别地,因为每个 write 请求通常是在一个 read 请求之后的,所以 write 的 coordinator 通常会选择上一次 read 中回复最快的那个 node。
这样的优化还能使得下一次读取的时候,这个节点更容易被选中,提高了 read-your-writes 一致性的概率。
EXPERIENCES & LESSONS LEARNED
Dynamo 的最大优势是客户可以通过调节 N、R、W 来达到期望的性能、可用性和持久性等级。
AWS 最常用的 Dynamo 集群是 (3, 2, 2) 的。
Balancing Performance and Durability
Since Dynamo is run on standard commodity hardware components that have far less I/O throughput than high-end enterprise servers, providing consistently high performance for read and write operations is a non-trivial task. The involvement of multiple storage nodes in read and write operations makes it even more challenging, since the performance of these operations is limited by the slowest of the R or W replicas.
在一些场景下,用户愿意牺牲持久性去换取更高的性能。此时,每个 storage node 可以维护一个 object buffer。每个操作会先存在 buffer 中,然后通过一个 writer 线程去写入到 storage 里面。这个优化可以将峰值流量期间的 P99.9 下降到原来的 1/5,并且只需要一个存放 1000 个对象的缓存即可。从图中还能看到,write buffering 能够对 P99.9 进行平滑。
当然,这种情况下,只需要一个节点挂掉,那么对应缓存里面的没有落盘的数据就消失了。To reduce the durability risk, the write operation is refined to have the coordinator choose one out of the N replicas to perform a “durable write”. Since the coordinator waits only for W responses, the performance of the write operation is not affected by the performance of the durable write operation performed by a single replica.
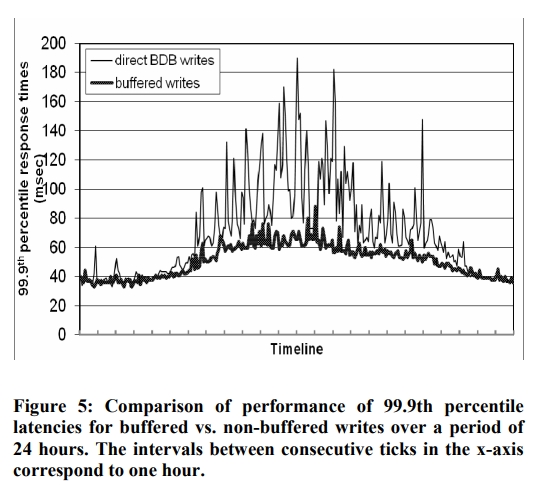
【Q】这里的意思我理解照样是写 W 个结果就返回了,写盘的那个节点很慢,但是我们不一定需要它成为那 W 个中的一个,我理解是这样。
Ensuring Uniform Load distribution
Divergent Versions: When and How Many?
从实验上来看,导致版本分叉增多的原因并不是故障,而是并发写数量的增加。
Client-driven or Server-driven Coordination
每个 Dynamo 节点都可以充当 read coordinator,但是只有 preference list 中的 node 才能当 write coordinator。这是因为这些 node 可以生成一个 version stamp,从而 causally subsumes the version that has been updated by the write request. 特别地,如果 Dynamo 的 versioning scheme 是基于物理时钟的,那么任何的节点都可以 coordinate 一个写入请求了。当然我个人理解就需要要原子钟那一套了。
另一种 request coordination 的方式是将 state machine 移动到 client node 上。客户端阶段性请求一个 Dynamo 节点,获取 membership 状态。这样的好处是能减少一跳。另一个重要的优势是,不再需要一个 load balancer 去均匀分发客户的负载了。
这个方案的劣势是 membership 不一定是最新鲜的。
Balancing background vs. foreground tasks
To this end, the background tasks were integrated with an admission control mechanism. Each of the background tasks uses this controller to reserve runtime slices of the resource (e.g. database), shared across all background tasks. A feedback mechanism based on the monitored performance of the foreground tasks is employed to change the number of slices that are available to the background tasks.
The admission controller constantly monitors the behavior of resource accesses while executing a “foreground” put/get operation. Monitored aspects include latencies for disk operations, failed database accesses due to lock-contention and transaction timeouts, and request queue wait times. This information is used to check whether the percentiles of latencies (or failures) in a given trailing time window are close to a desired threshold. For example, the background controller checks to see how close the 99th percentile database read latency (over the last 60 seconds) is to a preset threshold (say 50ms). The controller uses such comparisons to assess the resource availability for the foreground operations. Subsequently, it decides on how many time slices will be available to background tasks, thereby using the feedback loop to limit the intrusiveness of the background activities. Note that a similar problem of managing background tasks has been studied in [4].
Wisckey
https://dl.acm.org/doi/pdf/10.1145/3033273
Intro
LSM 相对于其他索引结构的优点是它为写操作提供了顺序访问。B 树上的更新可能包含很多随机写入,在 HDD 和 SDD 上的效率都不高。
为了支持有效率的查询,LSM 需要在后台进行 compaction,让 key-value 对们是 sorted 的。因此这带来了 50x 甚至更高的写放大。
在 HDD 上,随机 IO 比顺序 IO 慢了 100 倍,因此 performing additional sequential reads and writes to continually sort keys and enable efficient lookups represents an excellent tradeoff.
SSD 和 HDD 存在不同:
- SDD 上顺序写和随机写的差异不如 HDD 那么大
因此,执行大量的顺序 IO,从而避免后续的随机 IO,可能会浪费不少带宽 - SSD 的 internal parallelism 很高
- SSD 会因为反复写入磨损,LSM 的写放大会降低寿命
WiscKey 被设计来解决 SSD 上的这些问题。WiscKey 是键值分离的,键在 LSM 树上保持有序,Value 单独存在一个 log 中。换句话说,WiscKey 解耦了 key sorting 和 GC,而 LevelDB 将它们打包在了一起。这减少了在 sort 的时候移动 value 的写放大。特别地,这也减少了 LSM 树的大小,减少了 device read 的数量,也能让 lookup 的时候 cache 的效果更好。
这存在一些挑战:
- range query 的性能会收到影响,因为 value 不再是有序存储的了
在 Titan 的评测中,可以从 scan100 和 scan1000 中明显看到这一点。特别是小行宽、扫描行数多的情况下,Titan 劣势明显。
WiscKey 的方案是利用了 SSD 的冗余的 internal parallellism。 - WiscKey 需要 GC 去回收 invalid 的 value
它提出了一个轻量级的 online GC。它只需要顺序的 IO,对前台影响很有限。 - Key value 分离让 crash consistency 更有挑战性
WiscKey 利用了现代文件存储中的一个特性,也就是 append 操作永远不会在崩溃的时候产生垃圾数据。
BACKGROUND AND MOTIVATION
LSM
LevelDB
Write and Read Amplification
Write (read) amplification is defined as the ratio between the amount of data written to (read from) the underlying storage device and the amount of data requested by the user.
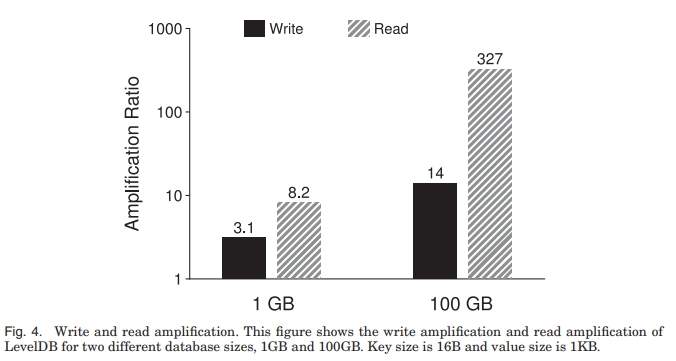
LSM 写放大高的原因是从 Li-1 层合并到 Li 层的时候,LevelDB 最坏情况下要读取 Li 层的全部 10 个文件,并在排序后重新写回 Li 层,从而产生 10 倍的写放大。
LSM 中存在两种读放大:
- 读一个 KV 的时候,LSM 可能要查询多个层级
Tier 层的 8 个文件加上 Leveled 层每一级的一个文件,总共可以是 14 个 SST 文件最多 - 在 SST 中查找 KV,要读取多个元数据块
包含 index block + bloom-filter block + data block。
例如,查找 1KB 的键值对,要读 16KB 的 index block,4KB 的 bloomfilter 和 4KB 的 data block,总共 24KB。
两个开销加起来,读放大能到 336。更小的 KV 会产生更高的读放大。
如下图所示:
- 写放大随着数据库大小增加的原因是从低 level 到高 level 压缩会多次写入。因为高 level 被 compact 了,文件平均数通常小于最坏情况的 10 个,因此没有达到最劣的情况
- 对于大数据来说,如果读取涉及到多个 SST 文件,而内存又不够存储所有的 SST 文件的 index block 和 bloom-filter,那么每次读取都会造成开销。
It should be noted that the high write and read amplifications are a justified tradeoff for hard drives. As an example, for a given hard drive with a 10ms seek latency and a 100MB/s throughput, the approximate time required to access a random 1K of data is 10ms, while that for the next sequential block is about 10μs—the ratio between random and sequential latency is 1,000:1. Hence, compared to alternative data structures such as B-trees that require random write accesses, a sequential-write-only scheme with write amplification less than 1,000 will be faster on a hard drive. On the other hand, the read amplification for LSM-trees is still comparable to B-trees. For example, considering a B-tree with a height of five and a block size of 4KB, a random lookup for a 1KB key-value pair would require accessing six blocks, resulting in a read amplification of 24.
Fast Storage Hardware
不同于 HDD,相比于顺序读取,随机读取性能在 SSD 上的表现更好。特别是如果随机读取是并发被执行的话,对于某些 workload 来说,总的 throughput 甚至能接近顺序存储。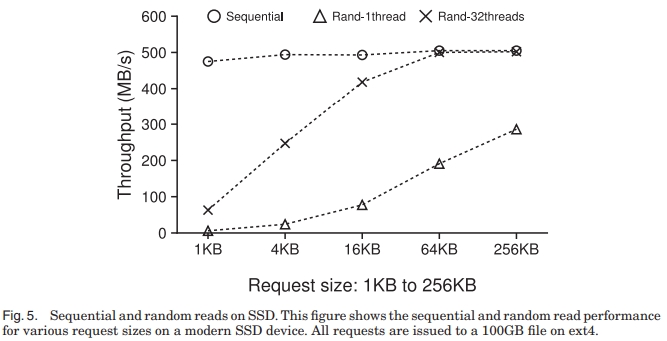
WISCKEY
复读了一遍 intro。
Design Goals
WiscKey 是一个单机的 persistent KV Store,从 LevelDB derive 出来。提供了类似 LevelDB 的 Put、Get、Delete 和 Scan 接口。
设计的主要目标:
- Low write amplification
避免浪费带宽、减少寿命。 - Low read amplification
避免降低吞吐、低效缓存。 - SSD optimized
- Feature-rich API
- Realistic key-value sizes
Key-Value Separation
对于一个有 16Bytes 大小的 key,1KB 大小的 value,key 写放大 10,value 写放大 1 的 WiscKey 来说,总的写放大是 (10 * 16 + 1024) / (16 + 1024) = 1.14。
WiscKey 较小的读放大能提高性能。虽然需要一次额外的 IO 去取 value,但是因为 WiscKey 上的 LSM 要更小,所以一次查询可能只会搜更少的 SST 文件。进一步的,LSM 的一部分甚至可以被缓存在内存里面,因此一次查询可能只需要一个随机读用来取回 value。
WiscKey 的架构如下所示。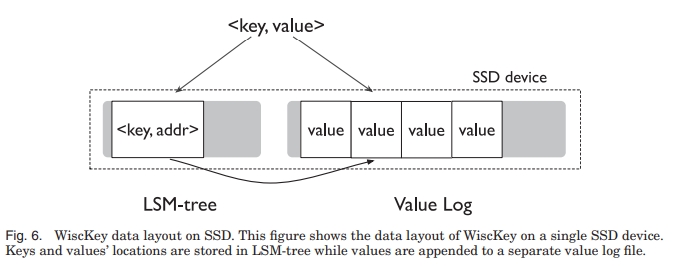
当用户写入 KV 的时候,value 首先被写入 vLog,然后 key 被加入 LSM,附带上 value 在 vLog 上的信息 <vLog-offset, value-size>。删除一个 key 只需要在 LSM 上删除就行了。在 vLog 中的 value 会在稍后被 GC 掉。
在读取时,首先读取 LSM 的地址,然后到 vLog 里面找 value。
Challenges
Parallel Range Query
为了使 scan 更高效,WiscKey 需要利用 SSD 的并行 IO 特性去 prefetch vLog 中的 value。
如果 user 请求一个 range 查询,Scan 会返回一个迭代器。WiscKey 会跟踪这个 range query 的 access pattern。一旦它开始请求一个 contiguous sequence of KV pairs,WiscKey 会开始顺序地从 LSM 读取一系列 key。因此,对应的 value 地址会被添加到队列里面,多个线程会从 vLog 中并行地获取这些 value。
Garbage Collection
在 LSM 的 compaction 中,WiscKey 不会同时回收 value。
一个简单的从 vLog 回收的方式是,首先扫描 LSM 拿到所有有效的 value 地址,然后 vLog 中没有被 LSM 引用的 value 就会被回收掉。显然这个方式很重,最关键的是,它只能适用于 offline 的场景。
WiscKey 的方案需要引入一个小的 data layout 变动。在存储 value 的时候,同时也要存储对应的 key。也就是 <key size, value size, key, value>。
WiscKey 的思路是让 valid 的值在 vLog 中处于一个连续的区段内。在这个区段的一端,也就是 head 的位置,是新的 value 被 append 的地方。在这个 range 的另一端,也就是 tail 的位置,是 GC 开始释放空间的位置。只有在 head 和 tail 之间包含了 valid 的 value 的部分,才可能在查询中被访问。
在 GC 时,WiscKey 首先会从 tail 读取一个 chunk,比如几个 MB 的 KV 对,然后会查询 LSM 树,看这些 key 是否被删除了。然后 WiscKey 会将 valid 的 key 添加回 head 位置。最后,它更新 tail 的位置,并释放空间。
为了避免 GC 过程中丢失数据,WiscKey 需要保证新 append 的 valid 的 value 和新的 tail 首先被 persist,然后才能真的去 free 掉 space。WiscKey 的方案是:
- 在 appending the valid values to the vLog 之后,GC 会调用一次 fsync
- 将这些新的 value 的地址和当前的 tail 同步地写入 LSM 中
tail 在 LSM 中存放的格式是<tail-marker, tail-vLog-offset>。 - 最后,在 vLog 中回收空间
Crash Consistency
WiscKey 保证了和 LSM 树同样的 crash guarantee,原因是利用了现代文件系统的一个特性。考虑一个文件包含了 b1 b2 b3 ... bn 这样的序列,然后后续 append 了 bn+1 bn+2 bn+3 ... bn+m 这些序列。如果发生了 crash,恢复后,会看到 b1 b2 b3 ... bn bn+1 bn+2 bn+3 ... bn+x 这样的序列,并且 x 是小于 m 的。也就是说,实际被添加的只可能是前缀,不可能是某个随机字节,或者多出来添加某些序列。进一步又可以推论,如果 X 在 vLog 中因为 crash 丢失了,那么所有在 X 之后被添加的也会丢失。
如果 key 在系统 crash 的时候丢失了,如果是 LSM 里面找不到的情况,会按照 LSM 的模式来处理。即使 value 已经被写进去了 vLog,它也可以在随后被 GC 掉。但是如果 LSM 中能找到key,就需要额外步骤。首先 WiscKey 会查询 value 的地址是否在 vLog 的有效范围,也就是 head 到 tail 这个区间内。如果不在,就说明 value 在系统崩溃中丢失了,从 LSM 中删除 key,并且通知用户 key 不存在。
Optimization
Value-log Write Buffer
Optimizing the LSM-Tree Log
LSM 的 log 中存放了 key 和 value。WiscKey 中 LSM 的 log 只存 key 和 value 的地址。进一步地,vLog 也会记录被插入了的 key,从而更好支持 GC。
如果在 key 在被持久化到 LSM 之前 crash 了,它们可以从 vLog 中被扫描从而恢复。但简便的做法需要扫描全部的 vLog 才能会的结果。为了减少这一点开销,WiscKey 会定期在 LSM 中记录 vLog 的 head:<head-marker, head-vLog-offset>。【Q】这里可以对比看下记录 head 和 tail 的不同原因。当一个数据库被打开之后,WiscKey 会从最新的 head 开始扫描 vLog,直到 tail。因为 head 被存储在了 LSM 树里面,所以 LSM 就 inherently 能够保证被插入 LSM 的 key 可以按照插入的顺序恢复,从而满足 crash consistency。
因此,从 WiscKey 中移除 LSM 的 WAL 是一个安全的优化。
性能
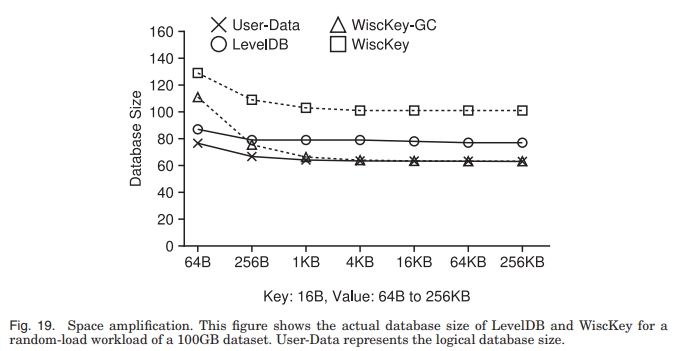
空间放大
Titan
Titan 的思路是将 RocksDB 中的 value 拿出来存,减少 Compaction 对 CPU 和 IO 的开销,但会带来空间放大。并且数据局部性差,所以范围查询性能较差。
Titan 将这些大 value 有序地存放在一些 blob file 中,并且保存了 value 对应的 user key 用来反查 RocksDB。反查的原因是 blob file 本身需要 gc,所以要通过 user key 来查询是否过期,这会带来一些写放大。
Titan 使用了 TablePropertiesCollector 的 feature。具体来说,它是定义了 BlobFileSizeCollector 这个 Collector,它会记录一个 SST 中到底有多少数据室放在 blob file 中的。
Titan 有两种 gc 策略:
- 定时 rewrite blob file
监听每次 Compaction 事件,从而维护每个 blob 文件中无效数据的大小。每次重写 invalid 率最高的几个文件,并更新回 RocksDB。旧的文件需要确保不再有 Snapshot 引用才可被删除。
具体来说,Compaction 此时只是计算和合并 SST 中的<blob_offset, size>了。在 Compaction 结束之后,是可以旧的 blob file 中到底有多少数据不再被新 SST 引用了。Titan 只有在 BlobFile 可丢弃的数据达到一定比例之后才会对其进行 GC。 - 在 LSM-tree compaction 的时候同时进行 blob 文件的重写
也就是在 Compaction 的同时写到一份新的 blob 文件中。因为不需要的 kv 会在 Compaction 的时候被过滤掉,也就相当于自动完成了 gc。这种方案的有序性会更好点,所以 scan 性能理论上会高。
这种方案要求 blob 文件也需要伴随着 SST 进行分层,从而带来写放大。并且也有不小的空间放大。因此,考虑到大部分数据都在最后两层,该策略只对最下面两层生效。
在一些场景中,Titan 能够带来收益。业界也有类似 Titan 的 KV 分离存储方案,比如 WiscKey 等。从测试结果来看,行宽越大,Update 提升越明显。从 1KB 时候的 2 倍不到,到 32KB 时候的大概 5 倍向上。

